
Welcoming Fred Grinstein as a 2026 Starling Lab Fellow

Spatial
We are delighted to announce that Fred Grinstein has joined Starling Lab as a 2026 Fellow, where he continues his research at the intersection of documentary practice, generative AI, and media authenticity.
Fred is a media executive, producer, and co-founder of Machine Cinema, based in Los Angeles. His career spans film and television, emerging technologies, and the creator economy. As Head of Non-Fiction Programming at Anonymous Content, he oversaw projects including Undercurrent: The Disappearance of Kim Wall (HBO), At the Ready (Sundance 2021), and Murders Before the Marathon (Hulu). His independent credits include Oscar short-listed Hidden Letters and Lowndes County and the Road to Black Power (Tribeca 2022). Earlier in his career he served as VP of Development at Viceland alongside Creative Director Spike Jonze, and as a Senior Director of Programming at A&E.
At Starling Lab, Fred has focused on how spatial intelligence and generative AI can be applied responsibly to non-fiction storytelling — and what verification frameworks are needed as captured and synthetic media become increasingly difficult to distinguish. His work includes developing a tranparent media “ingredient list” guidelines for AI creative workflows, research into 3D reconstruction of archival and historical materials, and contributions to Stanford’s EE292J, Designing for Authenticity.

After the Rubicon: AI, Creators, and the Design of Authenticity in Documentary Media

Spatial
We’ve Crossed the Rubicon
At this point, it is no longer useful to ask whether artificial intelligence will change documentary practice. That threshold has already been crossed.
AI is now embedded across the non-fiction content ecosystem: in historical documentary broadcast series, festival films, independent shorts, and throughout the contemporary creator economy spanning YouTube, Instagram, TikTok, X, and other social video platforms. What was once speculative has become common practice. The question has shifted from whether these tools belong in documentary to how they are being used, by whom, and with what kinds of disclosure and care.
This post does not attempt to settle those questions. Instead, it maps where we are right now — across established filmmakers, creators, platforms, and experimental formats — and asks what these early uses suggest about the future shape of documentary and the design of authenticity itself.
What’s Already Happening: Established Documentary Experiments
Before turning to creators and platforms, it’s important to ground this moment in serious documentary practice. Many of the most instructive experiments with AI are not happening at the fringes, but in projects led by experienced filmmakers working within real ethical constraints.

Voice as Archive
One of the earliest fault lines emerged around synthetic voice.
The controversy surrounding Morgan Neville’s biographical documentary about the late Anthony Bourdain, Roadrunner, centered not on the existence of AI-generated audio, but on its undisclosed use. Neville took a small number of sentences from a text exchange Bourdain had written and brought them to life with a voice clone. Once discovered, the backlash was swift — not because the words were fabricated, but because audiences felt the social contract had been surreptitiously breached. The lack of transparency left the filmmaker’s storytelling intentions exposed to concerns about posthumous consent.
That reaction stands in contrast to Andrew Rossi’s The Andy Warhol Diaries on Netflix, which also used generative voice technology, but did so transparently, in collaboration with Warhol’s estate, and with extensive public explanation. The same act — using AI to allow a person to posthumously speak words never actually recorded — produced a very different reception.
A third case, American Murder: Gabby Petito, complicates the picture further. Even with disclosure and family involvement, some viewers expressed discomfort with hearing private diary entries voiced aloud. Transparency is necessary, but it isn’t always sufficient.
Historical Re-Creations Where Archives Don’t Exist
Another rapidly expanding use case involves historical recreation.
In Free Leonard Peltier, director David France and collaborator Jesse Short Bull used AI-assisted recreations to visualize moments for which no archival footage exists, working in consultation with archival professionals and disclosing these choices clearly to audiences.
Similarly, the Sky History series Killer Kings represents one of the first broadcast television productions to use AI-generated reenactments at scale. The motivation was not novelty, but feasibility: historical series of this scope had become financially prohibitive using traditional methods.
In both cases, AI is not replacing archival evidence. It is extending what can be responsibly represented, allowing history to be visualized where silence once stood.
Identity Protection: Deepfake as Ethics
Some of the most ethically compelling uses of AI in documentary involve protecting human subjects rather than simulating events.
In Welcome to Chechnya, face-replacement technology was used to obscure the identities of LGBTQ+ refugees while preserving their emotional presence. Rather than blurring faces or hiding subjects in shadow, the film composited donated faces from activists onto participants, maintaining eye contact and expression.

A similar strategy appears in Another Body, which profiles victims of non-consensual deepfake pornography while using synthetic techniques to protect them from further harm.
In both cases, synthetic media arguably increases truthfulness by enabling stories that could not otherwise be told without erasing the people at their center.
Generative Form: What Is a Documentary Now?
Beyond content, AI is reshaping documentary form.
In ENO, the biographical documentary about music producer Brian Eno, the filmmakers designed an experience where a different version of the film is shown at every screening. Eno and his collaborator Brendan Dawes built a bespoke hardware unit called Brain One, which uses generative technology to reinterpret hundreds of hours of archive and interviews into a new experience — for the audience and even for the director himself. There is no definitive cut. Documentary becomes a performance, a living system rather than a fixed artifact.
A complementary counterpoint appears in Railbound, a short film by creative director Alex Naghavi, built from the documentary photography of Mike Brodie. Brodie’s still images, long recognized for their raw intimacy, document people living as hobos on trains. Railbound animates these photographs into motion using AI tools, while remaining explicit about its hybridity from the opening credits onward.
Developed in close collaboration with Brodie and grounded in respect for the original archive, the project uses AI to create continuity and movement while leaving every narrative and emotional decision — pacing, tone, sound, performance, color — in human hands.
Placed side by side, ENO and Railbound suggest two futures for documentary form: one oriented toward variability and system-level authorship, the other grounded in archival care and transparent interpretation. Together, they make clear that the question is no longer whether documentaries will become hybrid, but how that hybridity is disclosed, governed, and understood.
Creators and the Contemporary Documentary Ecosystem
These developments are not confined to traditional documentary spaces.
Across the contemporary creator economy, creators are increasingly acting as documentary participants. Often working solo or in small teams, they combine research, narrative, and visuals in ways that bypass institutional commissioning altogether.
AI functions here as a force multiplier, accelerating research, lowering production costs, enabling “impossible” visuals, and expanding who gets to attempt non-fiction storytelling.
This is the optimistic side of decentralization. Stories that would never clear traditional gates now find audiences. At the same time, the risks outlined in my previous post remain, and are amplified by scale.
Platform Anxiety: Authenticity After Abundance
One of the clearest signals that something fundamental has shifted comes not from critics or academics, but from platforms themselves.
In recent public commentary, Adam Mosseri, head of Instagram, has articulated a concern that goes beyond moderation or labeling. His argument is that authenticity itself is becoming infinitely reproducible. As AI-generated media grows indistinguishable from captured reality, the qualities that once made creators matter — being real, being present, being unfakeable — are no longer scarce by default.
What makes Mosseri’s perspective especially relevant is that he doesn’t frame this as a problem solvable through disclosure alone. Labels may help, he suggests, but they will inevitably fail as synthetic media improves. Instead, he gestures toward a deeper requirement: systems that can fingerprint real media at capture, establishing a chain of custody that allows platforms and audiences to distinguish documented reality from simulation.
In other words, Mosseri is pointing toward provenance, not just transparency. This aligns closely with the direction of research efforts like Starling Lab, which focus on authenticating origin rather than chasing increasingly sophisticated fabrications after the fact.
Mosseri also anticipates the human consequence of this transition. As synthetic content floods feeds, audiences will shift from default belief to default skepticism, paying more attention to who is sharing something and why. Surface-level disclosure won’t be enough. What’s required is context that can scale — signals about capture, authorship, and continuity that don’t rely on trust in any single institution.
When platform leaders begin publicly advocating for cryptographic provenance and capture-level verification, it signals that the challenge has moved from cultural concern to infrastructural necessity.
Acceleration in the Wild: Venezuela and Creative Proximity
If the earlier examples illustrate careful, intention-driven experimentation, recent events around Venezuela show how quickly creative practice can collide with live reality.
Following reports of political upheaval involving Nicolás Maduro, social platforms were inundated with misleading visuals: AI-generated images, recycled footage, and out-of-context photographs presented as breaking news. This dynamic was documented in reporting that showed how outdated visuals and synthetic imagery fueled widespread confusion during the unfolding events.
What made this moment especially revealing was not only the volume of misinformation, but the breadth of participation. The influx of synthetic imagery did not come exclusively from coordinated disinformation campaigns. Much of it emerged organically from within the AI creator community itself.
Well-known AI artists — many of whom focus on education, tutorials, and speculative storytelling — used the same tools they employ for short films and creative experiments to respond to the unfolding events. These works were not framed as documentary claims or journalistic interventions. They were acts of expression, produced in real time, using tools designed for cinematic realism.
One such example involved a popular AI creator demonstrating how Nano Banana Pro could generate a hyper-realistic, multi-panel “photo-documentary” imagining a fictional operation surrounding Maduro’s removal from power. The exercise was presented as a technical and creative demonstration, not reportage. Yet the imagery adopted the full visual grammar of breaking news.

None of this content was intended to mislead. But it underscores a real shift: creative tooling now sits so close to reality that expressive experimentation and perceived documentation can collapse into the same visual space, especially during moments of crisis.
Designing Authenticity Into the Experience
This collision brings us to the design challenge ahead.
If documentary forms are fragmenting — from feature films to feeds, clips, and explorable virtual environments — then authenticity can no longer remain implicit. It cannot live only in credits, press materials, or after-the-fact explanations.
The shift must be from “trust me” to “here’s how this was made.”
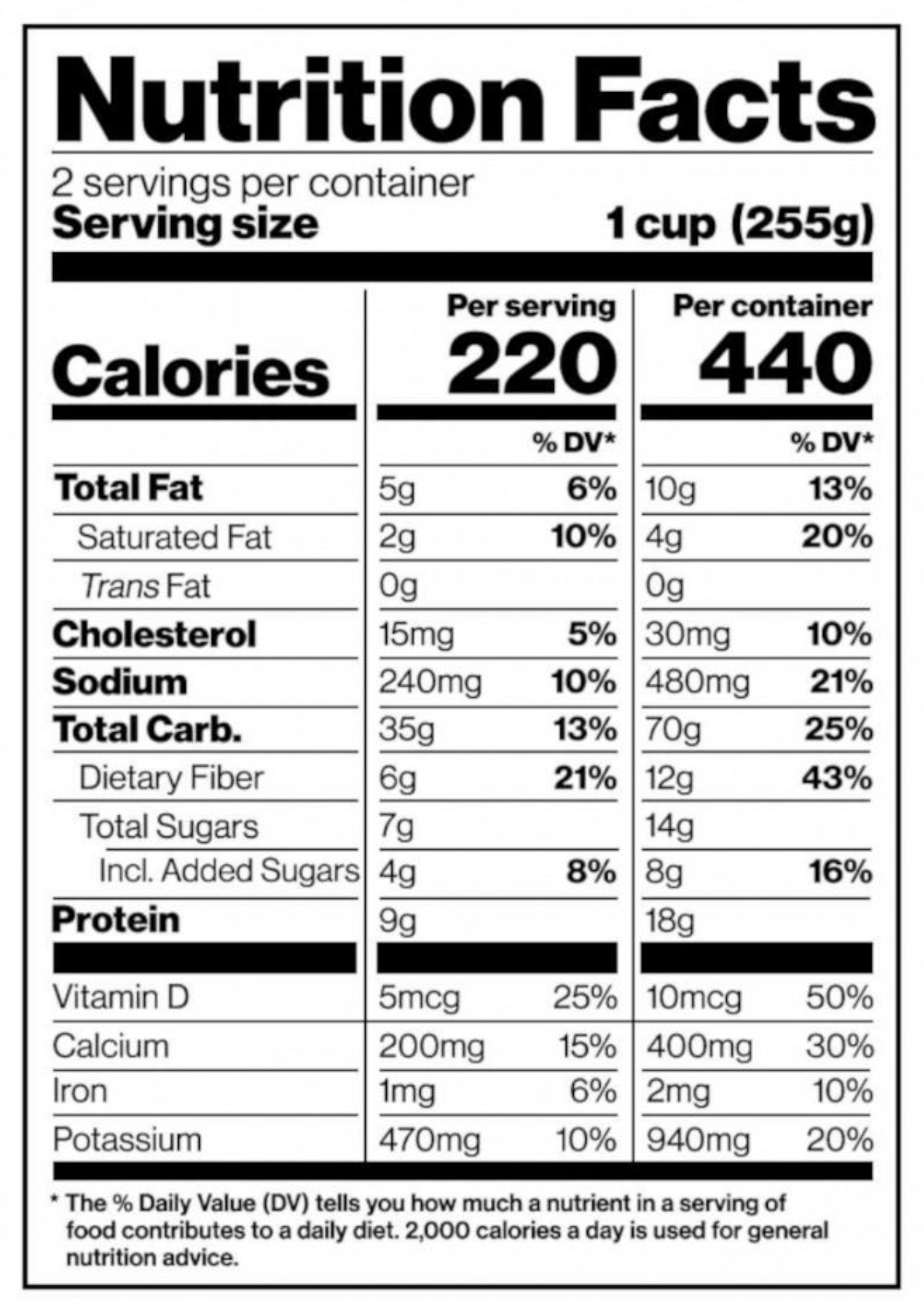
Consider the nutrition label, and what a phenomenon it’s been for the way people interact with what they consume and their health. It’s no coincidence that we talk about a media diet — media is something we consume too, and the relationship between maker and audience carries a similar obligation. What the nutrition label did for food — creating a shared, legible contract between manufacturer and consumer — is exactly the kind of user experience worth designing toward here.
Standards like C2PA are doing the foundational work, establishing the ingredients list: a verifiable record of what a piece of media is made of and how it got there. That’s the necessary starting point. But the infrastructure only matters if it reaches people in a form they can actually use.
The nutrition label works because it operates at two levels at once. Most people glance and move on — the presence of the label is itself a signal of accountability. The person who wants the full breakdown can find it. One standard, two levels of engagement, billions of transactions, all of it embedded in the act of buying food rather than added on top of it.
That layered dynamic is exactly what’s missing from how we currently present media provenance. We’ve been designing for the researcher, not the viewer. Movie ratings and game ratings point toward the right instinct: trust signals need to be ambient and low-friction before they can be meaningful. The original blue checkmark worked the same way — a simple icon implying a verified relationship between an identity and an institution.
Imagine extending that logic to YouTube, where most non-fiction content is now consumed. A small, color-coded icon — visible at a glance — tells you immediately where a piece of content sits on the spectrum from fully documented reality to openly synthetic work. A click, or even a QR scan, takes you deeper: into the metadata, the sourcing, the full ingredients list for anyone who wants it. Something that intuitive, baked into the YouTube experience, could just as easily travel to streaming platforms, broadcast, and social video. The standard expectation becomes: before you consume, you already know what you’re getting into, and you know where to go if you want to know more.
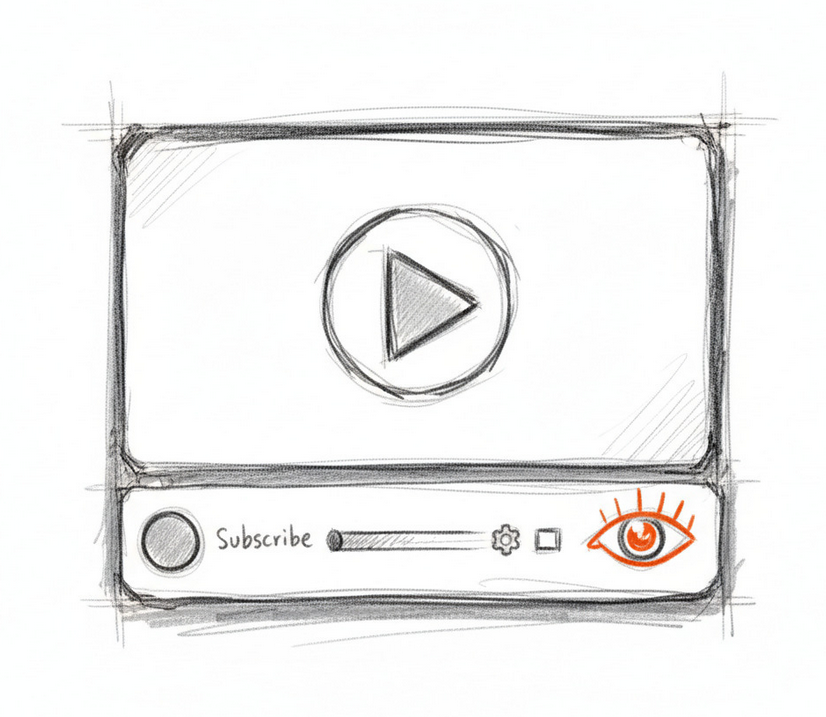
(UX Design suggestion: adding a simple icon inside the existing interface, color-coded to correspond to simple criteria akin to Movie or Game ratings, on a spectrum reflecting fact, fiction, and the space in between measured on a transparent system. Clicking the icon reveals verified metadata, + keyword tags for a range of formats including “verite”, “op-ed”, “investigative”)

(UX Design suggestion: After clicking eye icon, detailed information display including sources used to make the documentary, disclosure on AI usage, provenance info such as C2PA, and modification history info.)
That also means making meaningful distinctions that currently get flattened. An op-ed is not investigative journalism. A produced reality show is not a verified documentary. These don’t need to be condemned for what they are — but they shouldn’t share the same unlabeled space either. The label doesn’t judge the content. It just tells you what’s in it.
The technical foundation exists. What’s been missing is the will to treat media provenance as a consumer experience — something designed into the transaction, not bolted on afterward.
Experimentation Is the Point
There are no final answers. Documentary has always evolved through practice — through artists testing boundaries, audiences reacting, and norms slowly forming. AI accelerates this process, making both the risks and the possibilities more visible.
What matters now is not certainty, but intention. Transparency. Infrastructure that supports interpretation rather than replacing it.
Documentary remains one of the few spaces where society can rehearse how to live with ambiguity. In that sense, it is not being displaced by AI — it is being asked to lead.

How AI Is Accelerating Our Flawed Relationship With Documentary Truth

Spatial
Authenticity, Semiotics, and the Collapse of the Myth of Objectivity
Fred Grinstein is a documentary producer, media executive, and educator working at the intersection of non-fiction storytelling and emerging technology. His work spans legacy television, independent documentary, and research collaborations focused on media authenticity and synthetic media.
Through the Looking Glass (Again)
We’ve been somewhere like this before.
In 1896, early film audiences reportedly recoiled when a projected image of a train appeared to rush toward them. Whether or not the story is literally true, it captures something enduring about how new media can briefly destabilize perception. Early cinema collapsed the boundary between representation and reality, and over time audiences adapted. They developed a form of media literacy: an ability to read the frame, recognize artifice, and distinguish cinematic depiction from the world itself.
That arc — shock, adaptation, literacy — has become the story we tell ourselves about every new medium that emerges. It reassures us that confusion is temporary, and that our understanding will catch up.
In the summer of 2025, a short AI-generated video depicting bunnies bouncing on a trampoline circulated widely online. Many viewers initially assumed it was real. The reaction wasn’t panic or awe, but something quieter: casual plausibility. The video did not feel extraordinary. It felt believable. And unlike early cinema, there was no stable grammar for audiences to learn from — no consistent cues to decode, no shared visual language that reliably signaled illusion.
@rachelthecatlovers Just checked the home security cam and… I think we’ve got guest performers out back! @Ring #bunny #ringdoorbell #ring #bunnies #trampoline ♬ Bounce When She Walk - Ohboyprince
This is where the Lumière analogy begins to break down. We are no longer dealing with a medium that can simply be “read” into literacy. We are through the looking glass, in a media environment where the signals that once helped us distinguish reality from artifice are themselves synthetic, automated, and endlessly recombinable.
The discomfort many of us are experiencing now is not simply about fake videos. It reflects a growing awareness that the infrastructure we assumed was holding non-fiction media together may never have fully existed. What sustained trust instead was a fragile system of consensus built from institutions, conventions, and shared habits of interpretation. It went unexamined because it worked well enough.
That system has been under strain for some time. Artificial intelligence did not introduce the pressure, but it is accelerating it toward a more complete and undeniable state. Media literacy remains important. But unlike earlier media shifts, the pace, adaptability, and scale of synthetic media now evolve faster than shared norms can stabilize, making the emergence of a universally reliable literacy far less certain.
Part I: A Moment of Duality
AI is producing both inspiring and troubling outcomes at the same time. It is opening up creative possibilities, lowering barriers to entry, enabling stories that were previously too expensive, dangerous, or fragmented to tell, and expanding who gets to participate in cultural production. At the same time, it is amplifying disinformation, collapsing visual trust, and normalizing distortion at unprecedented speed.
It’s overly simplistic to frame this as a debate about whether AI is “good” or “bad.” A better question is: why was our media ecosystem so unprepared to absorb its effects?
One possibility is that we overestimated the strength of the trust systems we thought were already in place.
This strain did not emerge entirely by accident. Alongside scale, habit, and technological change, shifts in incentives and distribution in television, streaming, and social media gradually loosened the connection between credibility signals and shared accountability. What AI does is make that loosening impossible to ignore.
The Semiotics Problem
Non-fiction media has always relied on semiotics — visual and narrative signals that communicate seriousness, authority, and credibility. Camera framing, lower thirds, interview posture, typography, tone. These cues did not guarantee truth, but they created a workable proxy for trust.
Reality television played a significant role in blurring these signals. Journalistic tropes were reused as entertainment grammar across the genre. Sitdown interviews with competition reality contestants gave an air of “newsworthiness” to their presentation. Documentary filmmaking techniques once reserved for meaty topics like war zone coverage were deployed to bring dramatic weight to unusual workplaces, or to the personal lives of fabulous housewives. And without a newsroom and its journalistic standards, these “verite” style productions openly used scripts and direction to deliver for the viewer. This was not deception by design; it was optimization for scale, legibility, and production efficiency. At the time, it felt harmless.
I remember once describing a show I worked on as “basically like wrestling,” referring to the fact that viewers watch indifferently to the authenticity of the action before them. The comment stayed with me — not because it felt wrong in the moment, but because, in retrospect, it captured something quietly shifting. We were teaching audiences that the language of credibility could be separated from the obligation to truth.
This dynamic was not confined to reality television. Social media platforms soon abstracted the same signals even further. Fake newspapers succeeded not because their claims were persuasive, but because their fonts, layouts, mastheads, and column structures looked right. Credibility work was being done before content was even processed. Semiotics detached from institutional accountability.
You might even argue that the fake documentary style of TV sitcoms like The Office or Modern Family, or the success of found-footage horror films like The Blair Witch Project and Paranormal Activity, also diluted trust signals along the way, each one innocently exploring new entertainment territory.
AI completes this trajectory. Today it automates credibility aesthetics at scale. Semiotics made credibility legible, platforms made it viral, and AI makes it effortless.
The Collapse of Top-Down Narratives
For much of the twentieth century, non-fiction media operated within top-down structures. Broadcast news, major publications, and editorial gatekeeping created shared reference points. Some reflect with nostalgia on an era when newsmen like Walter Cronkite offered a broadly accepted standard for the daily record. In retrospect, it’s also generally acknowledged that these same individuals and the newsrooms they fronted lacked the representation we’ve come to expect — whether in terms of gender, race, or lifestyle. These systems were imperfect and exclusionary, but they provided consensus.
That architecture has fractured. Information now flows through preference-driven feeds, citizen journalism, influencers, and self-published media. This decentralization has expanded representation — a real and necessary benefit — but it has also dissolved shared baselines.
The warts of this system are uncomfortable. In a fully decentralized media environment, young creators with large audiences and no editorial oversight can publicly speculate about the Holocaust, not through evidence, but through the performance of doubt. This is not an argument against free speech. It is an acknowledgment of what unfettered access to broadcast power includes.
The problem is not that more people can speak publicly; it’s that we never designed shared norms, literacy, or infrastructure for a world in which everyone can.
Avatars are the logical endpoint of this shift. As authority fragments, trust migrates to interface, to the affect of a trustworthy performance, and to always-on availability. Synthetic personalities scale certainty and intimacy far more efficiently than institutions ever could.
AI did not cause this collapse. It accelerated it.

The Myth of Objectivity
Documentary has never been objective. That idea was always more aspiration than reality.
Filmmakers from Errol Morris to Werner Herzog have long argued that documentary media itself is not a transparent window onto the world, but a construction shaped by choices, context, and interpretation.
We see this tension across the documentary canon itself. Michael Moore’s films openly foreground his perspective, collapsing the distance between journalist and participant. Films like Exit Through the Gift Shop or Author: The JT Leroy Story openly embrace sleight of hand as techniques to deliver what their filmmakers see as a methods to unpack deeper more compelling truths about their dynamic subjects. Even highly polished “authorized” documentaries — celebrity-driven biographical series like Beckham where the subject participates as en EP in shaping the narrative — carry the aesthetic weight of documentary while transparently advancing a point of view.

Audiences have long understood this. We don’t watch these works expecting neutral arbitration; we watch them expecting interpretation. Documentary has always contained this elasticity between reportage and argument, between record and persuasion. Truth, in this tradition, emerges through investigation and transparent process — not through the camera alone.
AI makes this impossible to ignore. When images, voices, and scenes can be generated or altered, the fantasy of mechanical objectivity collapses. What remains is accountability.
Part II: From Authenticity to Infrastructure
If debates about documentary truth are to move forward, they must move past an obsession with detecting fakery after the fact.
This is where the work of Starling Lab becomes instructive. Rather than attempting to identify synthetic media once it has already circulated, Starling focuses on infrastructure for authenticity: methods to capture, store, and verify media across its lifecycle.
This provenance-first approach emphasizes establishing a verifiable chain of custody from the moment media is created, anchoring metadata such as time, location, and source at capture, and preserving it through secure storage and verification. The goal is not to define truth, but to reliably distinguish documented reality from simulation.
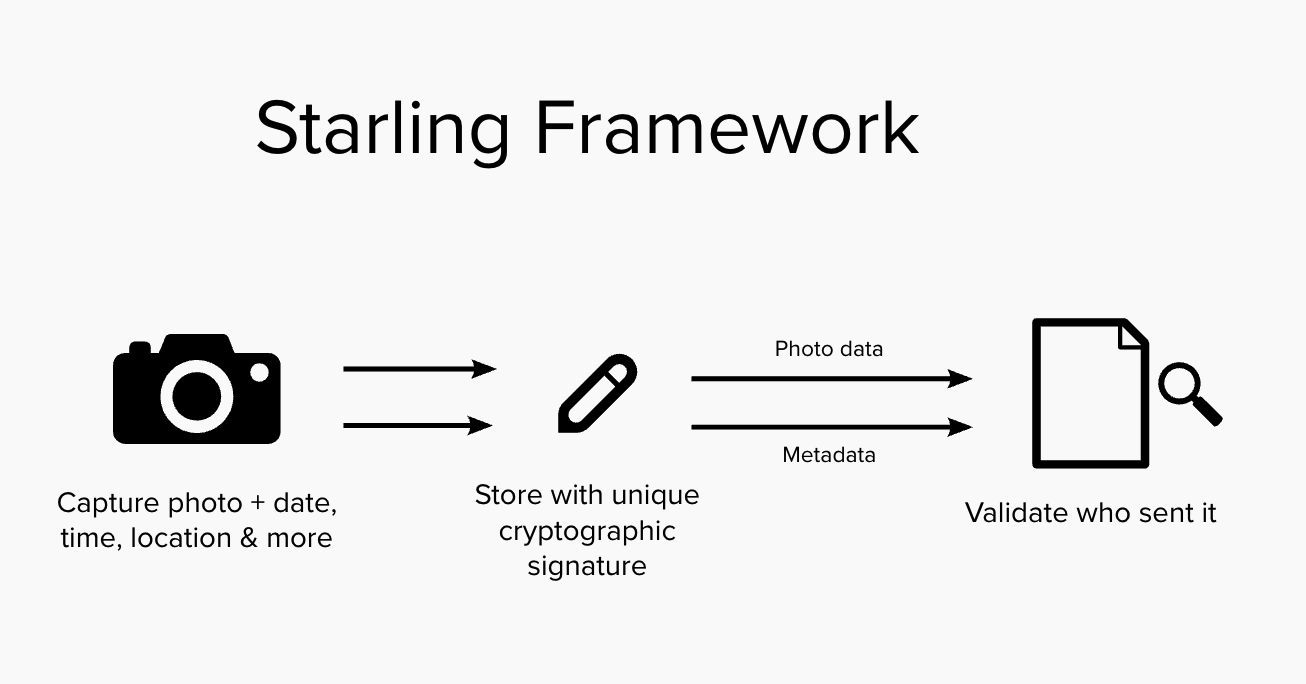
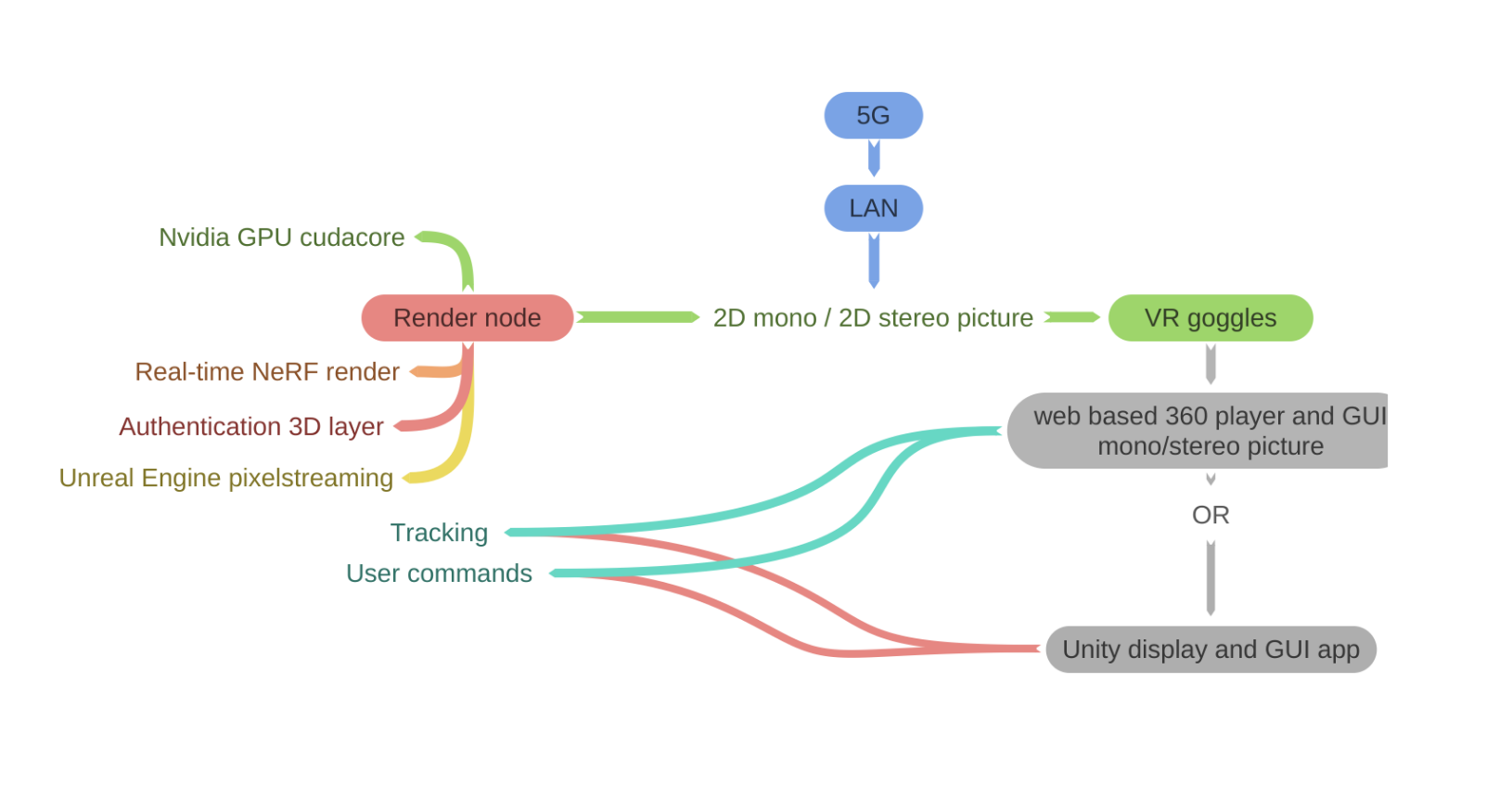
In the Starling Framework, a Root of Trust is the foundational source within a system where cryptographic trust is first established, ensuring the authenticity and integrity of digital records. Establishing a clear “root” is essential for creating a verifiable audit trail that tracks the creation and entire lifecycle of content, regardless of whether it is AI-created synthetic media or traditional content filmed with a camera. The Root of Trust serves as the bedrock for a “trustless” system, where any third party can independently confirm a digital asset’s origin and history without relying solely on the reputation of a centralized authority.
Capture
The Starling Framework prioritizes establishing this Root of Trust at the Capture phase — or, in the case of generative AI work, the Creation phase — as close to the original event as possible. Ideally, this is anchored in the hardware or firmware of a device, such as a camera’s sensor, a smartphone’s secure enclave, or a computer’s GPU, to bind “birth certificates” of authenticity to an asset before it can be manipulated at the user level. By systematically hashing and signing digital media at this earliest stage, the framework creates an immutable provenance trail that remains with the data throughout its entire lifecycle.
In the Starling Framework, both “real” content created with an actual camera and AI-generated synthetic content are treated equally. Both get “birth certificates” of authenticity. The framework provides the transparency necessary for audiences to evaluate what they are seeing from an informed position.
Store
Digital assets naturally decay due to hardware failure, media obsolescence, or malicious attacks, making resilient preservation essential. Documentary filmmaking, journalism, and other disciplines also require edits and adjustments to content as part of standard workflow: interviews are edited for brevity and clarity, photos are cropped and toned, and historical images are restored and repaired.
Starling addresses this by leveraging tamper-evident data structures and constant audits to demonstrate integrity over time and immediately expose changes. Integrity proofs from the capture step are registered on consensus-based ledgers (blockchain), creating an immutable record of the content and its time of creation that remains accessible even if original hardware fails.
Verify
Starling Labs embraces both human and technological approaches to verification, creating digital audit trails akin to a notary’s physical ledger.
Starling workflows surface cryptographic integrity evidence and immutable registrations, allowing audiences to evaluate the evidence for themselves rather than relying on blind trust. These methods automate complex parts of the verification cycle, removing opportunities for human error and providing real-time authentication.
Ultimately, this enables current and future inspectors to definitively understand the provenance and integrity of digital media throughout its entire history.
The Starling Lab Framework’s provenance and verification do not create trust, nor do they resolve meaning or ethics. But they help stabilize the preconditions for trust by establishing a shared and verifiable record of what happened, when, and where.
Without baseline agreement on those fundamentals, discourse collapses into endless skepticism. With them, we can argue productively about interpretation, responsibility, and impact.
In other words, authenticity infrastructure allows us to move the conversation up the stack.
The Opportunity
AI did not break the documentary. It revealed the fragility of relying on habit, authority, and convention to convey authenticity rather than on designed systems.
That realization is unsettling, and understandably produces fear and pessimism. But it is also clarifying.
The opportunity now is not to restore a mythic past of objectivity, and not to surrender to relativism, but to build infrastructure that acknowledges how non-fiction actually works: as a negotiated, interpretive, consensus-driven practice.
Today’s audiences expect credits at the end of a documentary that list the director, producers, music credits, and all the people who participated in creating the work. What we are suggesting would be an extension of those credits, functioning similarly to an ingredients list on food packaging. But instead of words printed on a cardboard box, it would be addresses on a blockchain ledger pointing to the primary sources used to create the documentary. Further entries could list the modifications made to those sources in the making of the film. In this way, audiences would know not only who made the documentary, but what raw ingredients went into it, and how they were processed to arrive at the final result.
Documentary sits at the center of this moment not because it is uniquely threatened, but because it has always operated at the boundary between fact and meaning. AI simply makes that boundary visible.
What we choose to build there — soberly, optimistically, and intentionally — will determine whether non-fiction remains a space for shared understanding, or dissolves into noise.
Limits of the Argument
This essay does not argue that artificial intelligence is the sole or primary cause of declining trust in non-fiction media, nor does it attempt to resolve the political, economic, or psychological forces shaping this moment. It also does not claim that new forms of media literacy will not emerge, or that decentralization is inherently harmful. Rather, it focuses on a narrower observation: long-standing weaknesses in how non-fiction media relied on consensus, semiotics, and institutional habit are now being accelerated by synthetic media at a scale that challenges individual cognition. The infrastructure questions raised here are not presented as sufficient solutions, but as necessary conditions for meaningful discourse to continue.

Immersive Worlds for Documentary Filmmaking
Immersive Worlds for Documentary Filmmaking
Authenticity in three dimensions for non-fiction storytelling
Fred Grinstein
Reading Time: 5min
Spatial

Prototypes
ComfyUI C2PA Signer
Tags
AI, Documentary, 3D
Share
Contents
Background
Context
Framework
TechnologyLearningsArchive

Fellowship Projects and Awards
![]()
Background
Artificial intelligence is increasingly sophisticated in creating, understanding, and interacting in 3D environments. Also known as "spatial intelligence," this emerging field is being pioneered by world-class researchers and engineers around the world. As our own contribution to the field, Starling fellow Fred Grinstein has begun to explore how this use of generative AI might be applied to documentary filmmaking and non-fiction narrative works to engage audiences.
As much as spatial technologies offer a promising future of immersive, informative experiences, they also blur lines between reality and simulation, posing risks to trust in records used in documentary filmmaking, as well as journalism, law, history, and other human rights fields that require verifiable ground truth.
Today's AI generated photos and videos—some convincing, and others mired in the uncanny valley—share a common trait that the AI generating them has no real understanding of the world. Current generative AI is like a newborn baby: object permanence, cause and effect, and the behaviors of solids and liquids are complete mysteries to it, resulting in the inconsistent and sometimes amusing quirks of some of today's AI videos seen online.
However, the next generation of more sophisticated AI understanding is already emerging. World models, which aim to not just visually approximate, but actually physically simulate the real world are upon us. Whether announced or not, all companies behind today's big foundational models are working on algorithms that will capitalize on opportunities in this field. These include industry titans like Nvidia and Meta's Reality Labs, as well as overnight unicorn startups like World Labs. Currently confined to the lab and a few first movers such as Odyssey and Marble, soon anyone will be able to create utterly convincing 3D worlds from any photo, video, or text prompt as a starting point. When simulated worlds have visual quality and behavioral accuracy that renders them indistinguishable from reality, what will that mean for practitioners of journalism, history, and law.
As Starling Lab researchers, the core value we can offer is no longer the technical excellence of our 3D reconstructions of the world—that bar is collapsing under rapid commoditization—but philosophical, ethical, and epistemic clarity. Our focus must evolve from how beautifully we can reconstruct the world to how reliably we can verify what it represents.
Vital professions like law, journalism and history are scrambling to understand the implications of artificial intelligence. They're even less prepared for the emergence of spatial intelligence and related 3D reconstruction techniques using generative AI. These innovations will necessitate new approaches to ensure authenticity. Therefore, we are proposing to create a new center that leverages the most cutting edge AI technologies to push the conventional boundaries of trust and provide a roadmap and recipe for practitioners to bolster authenticity for new types of trust.
Note: Following this project, we were informed that the building containing the murals had been leveled and the location cleaned up. The art is now gone in its physical form, but survives digitally.
http://starlinglab.org/wp-content/uploads/2026/01/dorothea_lange_pea_picker_woman_supersplat.mp4
Contents
Context
FrameworkTechnologyLearningsArchive
Context
Starling Lab, co-founded by Stanford University and the University of Southern California, has an award-winning track record of working on data integrity and cryptographic authentication of digital records. In 2025, Starling Lab has undertook a series of experiments exploring Gaussian splat reconstructions of archival media—transforming still and video assets into immersive, explorable 3D environments.
We partnered with documentary filmmaker David France, experimenting with scenes from his seminal story around the AIDS crisis in How to Survive a Plague.
We also dug into the U.S. Library of Congress collection of 1930s and 1940s historical photography of the Great Depression, Dust Bowl, migrant workers, and incarceration of Japanese-Americans during World War II.
At the outset of this project, our emphasis was on the technical R&D of creating Gaussian splat-based immersive experiences from fragile, analog-era materials. At that time, 3D reconstruction required at minimum scores, and usually hundreds or thousands of technically perfect images. Even with unlimited images, many subjects—finely detailed, translucent, and thin materials such as hair, glass, and tree leaves—were difficult or impossible to reconstruct. For that reason, attempting to create 3D reconstructions from documentary films, or photos and videos found in historical archives was a significant technical challenge and area of focus.
A recently popularized technique, Gaussian splatting made reconstructing those previous subjects possible. Encouraged by initial results, we attempted to push the technique as far as it would go. Given that with historical photos, there was often only a single image, we asked the question: How might we 3D reconstruct a historical scene with only a single frame from a documentary film or a single black and white archive photo?
The broader goal has been to evaluate the creative and evidentiary potential of spatially reconstructed archives as a new mode of engagement with verified historical content. Would a 3D reconstruction of a historical event aid in understanding and open up new avenues to explore?
These experiments, which demonstrated that 3D reconstruction of a single historical image was possible, have validated early instincts: that 3D world generation from stills and low-dimensional media would soon become a ubiquitous capability. A year later, this has proven true—from Apple, Nvidia, Google, OpenAI, WorldLabs, and Odyssey Systems, and countless open-source and academic projects are now building similar pipelines.
As spatial intelligence opens new opportunities for journalists, lawyers, and historians there are many unfolding questions about how these fields can authenticate these new AI assets:
Building Trust in 3D Reconstruction Pipelines: At each step as 3D creators ingest content and extend scenes with generative AI, trust needs to be built to ensure the authenticity of the data and the models is assured.
Spatial Understanding: As 3D scenes use a variety of generative tools there are opportunities to develop graphs of semantic understanding that can improve the fidelity of 3D scenes but also provide classification of objects and concepts in the scene.
User Experience: As 3D models are trusted to create digital twins for simulation or exploration, we need new user interfaces that allow for inspection of both the original captures and the synthetic objects.
Starling Lab fellow Fred Grinstein sought to establish new guidelines and develop and test solutions along the boundaries between authentic and synthetic media in 3D spaces, ensuring the reliability and trustworthiness of digital records.
http://starlinglab.org/wp-content/uploads/2026/03/marble_demo_slow_with_still.mp4
Contents
Framework
TechnologyLearningsArchive
Framework
The Challenge
When we began the project in 2025, the possibility of creating an immersive environment from a single photo or short clip of video was an open question. Our focus was technical, reading technical papers and trying out various approaches using AI diffusion models to create 3D environments. Progress was slow and labor intensive.
Images were fed into video diffusion models in order to synthesize additional images showing more sides of the scene, that could then be fed back into the same models to create even more aspects of the scene until a complete 3D model could be created. The work was time consuming and error prone as slight deviations from image to image would be amplified and thwart the 3D reconstruction.
However, while working on this problem other groups in spatial intelligence were also working on this problem. With the launch of world model services such as World Labs' Marble in [month] 2025, we came to the realization that, as Fred Grinstein put it, "Soon anyone will be able to create 3D worlds from anything."
We realized that we could leave the technology to others and focus instead on philosophical, ethical, and epistemic clarity.
From Reconstruction to Verification
This leads to a renewed articulation of Starling Lab's mission:
Capture → Store → Verify
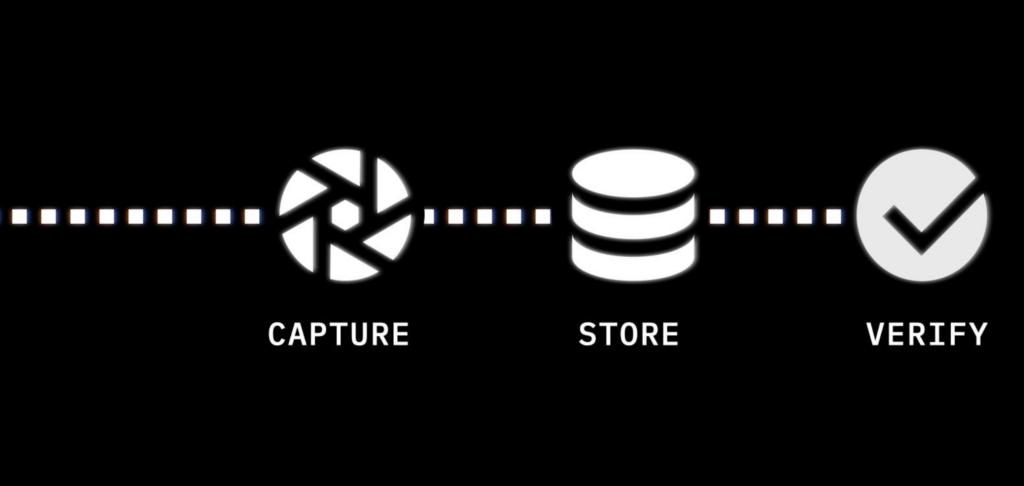
Capture
We aim to establish a root of trust in the asset's authenticity as early in its lifecycle as possible by binding authenticity metadata to an asset as close as possible to the moment it's created. We promote the creation of stronger, richer digital items in two ways: by systematically hashing and signing digital media to preserve integrity, and by placing assets alongside metadata and provenance markers.
Store
Digital assets decay. Even with the best of intentions, some of humanity's most vital digital records have been lost due to hardware failure, media obsolescence, human error, malicious attacks, natural disasters, or economic collapse. We address this problem in the storage step by leveraging tamper-evident data structures and constant audits to ensure and demonstrate preservation of integrity over time and exposing tampering. We also redundantly place data in several locations and use distributed and peer-to-peer systems to lower the risks caused by too few critical points of failure.
Verify
Starling Labs embraces both the human and technological approaches to verification. We create audit trails akin to those evaluated by real-world notaries who stamp a document and record it in their physical ledger. Our workflows capture the attestations of both experts and others throughout a digital asset's lifecycle. We surface cryptographic integrity evidence and immutable ledger registrations.
For this project we’re added an additional step we're referring to as a nutrition label for generative AI outputs.
Nutrition Label
The next phase emphasizes the creation of verification and authentication systems for synthetic or hybrid media—a kind of "nutrition label for digital reality."
This system would communicate to audiences:
- What data sources a scene or image derives from
- What transformations were applied
- Which layers are verified, synthetic, or uncertain
- How provenance metadata persists through remixing and AI generation
Such a "media ingredient label" could become a cultural expectation, much like nutritional transparency in food labeling—even if most people don't read it, its presence builds trust.

Contents
Framework
TechnologyLearningsArchive
The Prototype
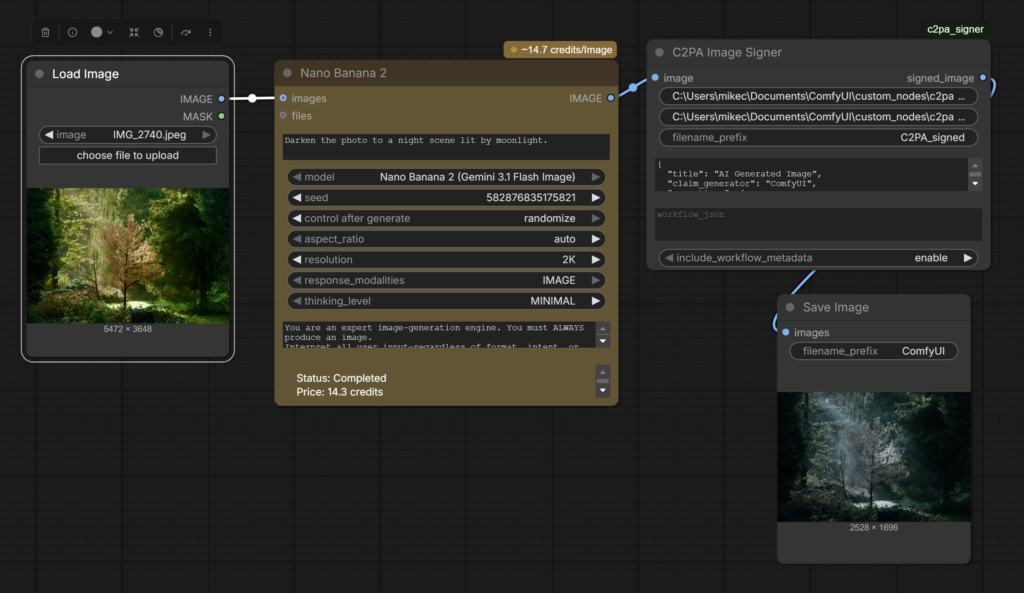
ComfyUI Prototype
You can buy a camera from Leica, Nikon, Canon, or Sony capable of embedding C2PA provenance metadata into the photos they take (whether they allow you to use the feature is another matter). Google Pixel 10 cameras automatically embed C2PA provenance metadata by default as does OpenAI’s Sora. However those implementations treat each photo or AI output as a discrete and independent object, and assume that the images won’t be used as ingredients in a larger work combining multiple media types and AI.
Through our work in this project we observed that photos, videos, and diffusion model outputs were often small individual components or ingredients that went into making a larger AI work. We saw a need for end users to be able to know everything that went into making a work – all the photos, videos, AI processes, and other transformations.
To that end we chose to target ComfyUI, an open source AI authoring suite that can be used for everything from upscaling and editing photos, to composing music, AI video creations, and complex workflows. We designed a prototype for ComfyUI that inserts C2PA credentials into AI creations, with the goal of providing information on everything that went into created media.
Our open source Comfy Node encapsulates the entire workflow with C2PA metadata, including all transformations, AI processes, which models were used and the specific settings. This not only informs users, but allows them to recreate the works themselves following the embedded recipe, enabling users to verify the process themselves.
Designing for Authenticity Class
Our fellows and classes at Stanford are working with a unique collection of 35,000 images and videos taken in North Korea. Captured by former AP and National Geographic photojournalist David Guttenfelder (now with NY Times), these one-of-a-kind visuals document life at all levels in North Korea, from the leadership to people going about their daily lives. This serves as the foundation of an ongoing experiment to create immersive experiences from 2D photos.
These approaches are opening up new opportunities in experiential journalism. We're also exploring collaborations with world-class journalists to better understand the impacts of runoff from abandoned mines in rural America and answer historical mysteries from the Vietnam War.
A unique opportunity emerged from the materials we'd been authenticating from North Korea—a place notorious for propaganda and which hasn't been visited by western journalists for half a decade. We set out to test the limits of 3D reconstruction and see if audiences might be able to "visit" North Korea in virtual reality—with as little as a single authenticated photograph. This material was already being presented in a Stanford course called Electrical Engineering 292J, "Designing for Authenticity."
Designing for Authenticity students applied Starling Lab's "Capture, Store, Verify" workflow to the unique set of photojournalistic images photographed in North Korea by Guttenfelder. Additionally, students were challenged to attempt to create explorable immersive 3D environments from the photographs using cutting edge 3D visualization and AI techniques running locally on Nvidia GPU hardware. This project often required taking a single photo and using the information in it, combined with additional information gathered from news reports, additional images including satellite imagery, and using AI to generate the additional visual materials necessary to create a 3D model. In doing so, students explored the tensions and boundaries of using AI and 3D visualization to tell journalistic stories, and proposed approaches for responsibly using these techniques while maintaining authenticity.
Contents
Context
Framework
Technology
LearningsArchive
Technology
Evaluating Workflows and Algorithms for 3D Reconstruction
As mentioned earlier, it is typically necessary to have hundreds or thousands of images from a wide variety of angles of a scene in order to successfully reconstruct it in 3D with traditional techniques. The historical images we worked with often only had a limited number of views and sometimes only a single image of a given scene. The resolution and quality of the historical images varied greatly, from highly detailed black and white photography from the 1930s and 1940s to low resolution camcorder video filmed in the early 2000s.
- Gaussian Splatting - the most successful technique for creating photorealistic scenes from extremely sparse image sets
- Nvidia InstantSplat - this recently released technique (which also uses Gaussian Splats) showed tremendous promise, able to generate 3D from very sparse sets of images
- Neural Radiance Fields – also successful for reconstruction but less realistic than splats
- Photogrammetry – High requirement for input images and inability to render complex organic scenes and low data situations, made this technique only appropriate for buildings and other hard-edge scenes with ample input data.
- World Lab’s Marble – An all-in-one cloud-based paid world model-based reconstruction service that creates small Gaussian splat worlds (marbles) from input images and videos.
AI Diffusion Models Evaluated:
- FramePack - this Stanford University-developed software allows Tencent's open source GenAI video model, Hunyuan, to efficiently run on local Nvidia GPUs. The software was first released as an Alpha within days of the start of the course and quickly became the go-to software for generating additional images from a single source image because of its open-source nature, speed, reliability and controllability.
- Wan2.1 - this Alibaba-developed open source GenAI video model was evaluated but not used because of difficulty controlling output.
- Commercial GenAI models - Google Veo 2&3, Runway Gen4, Luma AI Dream Machine, Kling, Higgsfield, OpenAI's Sora, and many other commercial software were also evaluated. None of these were successful for various reasons: Some claimed a worldwide copyright in perpetuity to reuse any material submitted. Some had opaque content controls that would randomly refuse to work on images deemed inappropriate. Some AI were essentially uncontrollable and could not be used reliably. And for others, the quality of the visuals was cartoony and unrealistic.
Sample Outputs
Due to embedding limitations in this document, it's best to visit the following samples via the provided web link. Once the experience loads, you can pan around and zoom in, experiencing these rare scenes in 3D—even though we only built them from an authenticated 2D image.
Contents
Learnings
These Starling experiments highlight where AI reconstruction meets the limits of historical fidelity:
A lost generation of video: A surprising result of our experimentation in making 3D reconstructions from historical imagery, was the extreme challenge of video recorded from the 1980s through the early 2000s. At the outset of the project we began with black and white photos taken by photographers working for the U.S. government Farm Security Administration and War Relocation Authorities in the 1930s and 1940s. The gelatin silver prints held by the Library of Congress are sharp, high-resolution (as high as 8K), and very information dense. Even Civil War photographs held enough detail to successfully 3D reconstruct using modern techniques. Diffusion models easily interpreted the scenes depicted in one-hundred-year-old photos and assisted us in creating additional viewpoints in order to 3D reconstruct.
Buoyed by these early successes, it seemed that any historical moment of any era captured by a camera could be brought to life in an immersive 3D experience. Surely if we succeeded with some of the oldest photos then more modern eras’ images benefitting from more modern technology would be even easier, we reasoned. We were wrong.

We soon realized not every era would be as easy when we tried to tackle the history of the AIDs crisis as depicted in David France’s seminal “How to Survive a Plague”. WIth the permission of France, we extracted stills from camcorder and broadcast video from the 80s through the early 2000s. Video recordings were an attractive target. Lengthy videos gave us a huge selection of moments to choose from, and if the camera operators moved through a scene, that might give us the additional view points we needed to make 3D reconstructions.
However, what we found was that in the video of the 1980s-2000s, standard definition ruled at roughly 720x480 pixels and not very sharp pixels at that. This was only a small fraction of the resolution of the black and white photography we had tried previously. Our attempts to create 3D reconstructions from the footage were stymied by mushy visuals and low resolution. Diffusion models failed to correctly interpret the scenes and had trouble understanding objects in the scene or even correctly identifying humans. We tried upscaling with commercial and open source upscaling tools, but given the lack of visual detail in the source material, file sizes and resolution got bigger, but the underlying information and detail in the scene was not enriched.
While in the late 2000s, digital devices would deliver high-resolution, sharp footage, the mushy analog camcorder footage from the 1980s to the early 2000s we dubbed a “lost generation” as far as 3D reconstruction was concerned.
Contextual truth: Reconstruction fidelity ≠ historical authenticity. Creating 3D reconstructions requires many views of a subject. The fewer source images you begin with, the more you need to recreate with AI. In our experiments creating 3D environments from single images, we relied heavily on diffusion models to fill in gaps, meaning that while our 3D environments are statistically probable, they are not necessarily accurate to the real-world scene.
As we were recreating the scene, a question that arose was when does an immersive experience based on historical material cease to be informative and become misleading? It seems impossible to pick a precise point when this threshold will be crossed, and likely it is different depending on the person and the intended use of the simulation.
While not ideal, this tradeoff can be acceptable if it is made transparent and so that audiences can make informed choices and decisions about what they are seeing. What matters most is the paper trail—knowing the provenance, source lineage, and process metadata.
The pace of technological development regularly outpaces our expectations: From "is it even possible?" to "it's easy" in a matter of months. When we began this project we weren't sure what we were proposing—to create immersive worlds from single images—was even possible. We focused on the technical, trying to establish the feasibility of doing this, and exploring techniques to do so. While we achieved our goal, other groups were working on the same. In [date] World Labs released its beta of Marble, an easy to use online tool for creating 3D Gaussian splat worlds from a single image.
This becomes the storytelling pivot: not only how we rebuild the past, but how we prove what we've rebuilt.
Contents
Context
Framework
Technology
Learnings
NextSteps
Archive
Next Steps
The greatest challenge facing provenance and verification systems isn't technical—it's adoption. C2PA and related frameworks have struggled to gain traction because they impose costs on creators without offering commensurate benefits. Verification feels like homework rather than opportunity.
The Starling approach reframes this dynamic by aligning authenticity practices with creators' existing motivations. The rise of generative AI has created an unexpected catalyst: creators are now deeply concerned about establishing clear ownership claims over their work, both to protect against unauthorized AI training and to defend their intellectual property in an increasingly murky legal landscape.
This concern creates a natural alignment. The same provenance documentation that establishes authenticity for journalistic or historical purposes also creates a defensible copyright trail. When a photographer cryptographically signs their original capture and logs it to an immutable ledger, they're simultaneously creating evidence of authorship and evidence of authenticity.
Companies operating in adjacent spaces recognize this opportunity. Startups are building infrastructure specifically designed to help creators document and defend their copyright claims through rigorous provenance tracking. While their primary motivation is intellectual property protection rather than journalistic integrity, the underlying technical requirements overlap substantially.
This suggests a strategic opportunity that would benefit copyright holders as well as journalists, historians, and legal professionals : rather than advocating for verification as an ethical obligation, we can embed these practices directly into workflows creators are already motivated to adopt. Provenance becomes not a burden imposed from outside, but a natural byproduct of protecting one's creative and economic interests.
The implications extend beyond individual creators. Media organizations, archives, and documentary filmmakers all face pressure to demonstrate the authenticity of their holdings—pressure that will only intensify as synthetic media becomes indistinguishable from captured reality. By connecting verification to financial self-interest, we transform provenance from a moral duty into a market advantage.
Emerging Vision: Synthetic Infinity
Generative AI is producing an unprecedented flood of visual content. The economic logic is relentless: synthetic imagery is cheaper, faster, and infinitely customizable compared to captured media. Within a few years, the majority of images encountered online will likely be generated rather than photographed.
This abundance creates a paradox. As synthetic media becomes ubiquitous, authenticated captures become more valuable, not less. In a world where anyone can generate a photorealistic image of any scene, the ability to prove that a particular image represents something that actually happened becomes a scarce and precious commodity.
Starling Lab's work positions us at exactly this inflection point. Our experiments with 3D reconstruction from archival materials demonstrate both the promise and the peril: the same techniques that allow us to create immersive experiences from historical photographs can also be used to fabricate convincing false realities. The difference lies entirely in the paper trail.
Looking ahead, this project points toward several concrete directions. First, we aim to develop a functional "nutrition label" protocol that can be applied to any piece of media, displaying at a glance what sources it derives from, what transformations have been applied, and what confidence level viewers should assign to different elements. This label would be machine-readable as well as human-readable, allowing automated systems to assess and propagate trust through chains of derivative works.
Second, we see significant potential in partnerships that span the archival, copyright, and provenance-technology sectors. Libraries and museums hold vast collections of authenticated historical materials that could serve as ground truth anchors for 3D reconstructions. Copyright-focused companies are building infrastructure that overlaps with our verification goals. By connecting these ecosystems, we can create network effects that accelerate adoption.
Third, we're exploring methods to embed provenance tracking directly into creative pipelines, generating "paper trails" in real time as artists and journalists work. Rather than treating verification as a post-hoc audit, this approach makes authenticity documentation an invisible but persistent feature of the creative process itself.
Finally, none of these technical systems will matter without corresponding efforts in media literacy. Audiences need to understand what verification markers mean, how to interpret them, and why they matter. This educational component is essential to building the cultural expectation that authenticated media should be the norm rather than the exception.
Our belief is that with the adoption of authenticity markers, audiences will be able to make informed choices in their consumption of authentic and synthetic media. The tools have changed since we began this work, but the core insight remains: trust is built through transparency, and transparency requires authenticity infrastructure.
Near Term Actions:
Building on the foundation established through these experiments, we propose the following near-term actions:
Prototype Development: Develop a working prototype of the "nutrition label" system applied to one archival 3D reconstruction. This prototype would demonstrate the full pipeline: authenticated source materials, documented AI transformations, and a user-facing interface that communicates provenance clearly.
Practitioner Guidelines: Produce documentation and guidelines for journalists and documentary filmmakers seeking to incorporate 3D reconstruction into their work responsibly. These guidelines would address questions of disclosure, labeling, and the ethical boundaries of generative enhancement.
Contents
Context
Framework
Technology
LearningsArchive
Archive
Also by this author
Radiance Fields

Spatial

Starling Lab’s verifiable radiance fields prototype is an experimental pipeline for embedding cryptographic provenance into 3D reconstructions using Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). As radiance field techniques are combined with generative AI to create navigable environments from sparse, or even single, 2D photographs, they blur the boundary between documented reality and algorithmic interpolation. The verifiable radiance field prototype anchors specific points in a reconstructed scene back to their authenticated source images, creating a tamper-evident chain of custody that persists through the non-deterministic reconstruction process.
YEAR
2024-26
LINKS
Exploring Authenticity in NeRF and 3DGS
By Basile Simon
Paper: Verifiable Reality, comparing streaming performance for both algorithms
The Problem
3D reconstruction is shifting from traditional 3D capture for photogrammetry and radiance fields, created from scores to thousands of images of a scene, to generative-AI-augmented methods that recreate convincing environments from far fewer images. The tradeoff is that these methods fill spatial gaps algorithmically, generating plausible geometry, lighting, and texture where no source photograph exists. Without a way to distinguish authenticated representations from hallucinated data, these models risk being dismissed in high-stakes environments like courtrooms, newsrooms, and archives — regardless of how much genuine source material they contain.
JOURNALISM Field reporters using 3D capture to document conflict zones or disaster sites need editors and audiences to trust the resulting environment. Verifiable radiance fields allow any point in a published 3D scene to be traced back to its source image and that image’s content credentials.
HISTORY Spatial documentation of historical sites produces radiance field models from archival and contemporary photographs. Embedding provenance preserves the distinction between what was photographed and what was computationally inferred.
LAW For 3D scene reconstructions to serve as evidence, chain of custody must be demonstrable. A verifiable radiance field links each element of a 3D environment to its forensic origin, distinguishing documented geometry from algorithmically generated fill.
JOURNALISM
Radiance Fields technology allow newsrooms to deploy hyper-realistic 3D reconstructions of complex scenes, and in record time. A layer of verifiability might support journalists in defending their reporting against accusations of AI hallucination.
HISTORY
This technology protects digital heritage collections against revisionism by binding “digital twins” of cultural sites to their unique physical origin.
LAW
We wonder what might be the path to supporting non-deterministic AI models into becoming court-admissible records. We believe that hardware-anchored signing and cryptographic registrations might provide the “transparency indicators” required for forensic examination.
The Solution
Our verifiable radiance field work grows out of active spatial documentation projects, including 3D reconstruction of Japanese American internment camp sites, Armenian heritage sites, and conflict zones Ukraine, where the distinction between captured and computed reality has direct consequences for historical and legal integrity.
We bind C2PA content credentials to specific points within a radiance field, linking them to authenticated 2D source images. A multi-ledger approach, using chains such as Avalanche, Numbers, Filecoin, and ISCN, creates redundant, tamper-evident records. In practice, a viewer navigating an immersive environment can query any region and see which source photographs contributed, when they were captured, and whether their content credentials are intact. The system is designed to function on standalone VR hardware via optimized streaming protocols.
This work is at an early experimental stage. The core open problem: radiance field reconstruction is non-deterministic, meaning the same source images can produce slightly different 3D outputs on different runs. Maintaining a verifiable link through a process that doesn’t produce identical results each time remains an active area of research, and we welcome collaboration from teams working on deterministic or reproducible reconstruction methods.

World Model News: Walking Around Inside a Photograph with Google DeepMind Genie 3
Spatial
I fed a 1930s Dust Bowl photograph of migrant workers by Dorothea Lange into the latest iteration of Google DeepMind’s Project Genie and within seconds I was walking around inside it. A shack lay ahead. I turned around and the scene behind me (a scene that doesn’t exist in the original photograph) was already there, rendered in dusty period-accurate detail, all in keeping with the source photo.
Beyond the borders and viewpoint of the original photograph none of it was real. Everything else was generated by the Genie 3 world model, which used the photo as a jumping off point. As I navigated the scene it looked like an extension of the photo documentation of that place, but in fact it was synthetic visuals. The distinction between the real and the synthesized is becoming a pressing issue in spatial media as generative AI models like Genie 3 become more capable and produce ever more realistic imagery.
Input photo of 1930s era migrant workers

Genie 3 is the first public release of Google DeepMind’s Project Genie world model, which launched on January 29, 2026 for AI Ultra subscribers in the United States. It followed two earlier versions, Genie 1 in February 2024 and Genie 2 in December 2024, that were demonstrated but never released to the public.
The technical approach is fundamentally different from reconstruction methods like Gaussian splatting. Where a splat scene derives its geometry and color from dozens or hundreds of real photographs or frames of video of a real place, Genie 3 generates frames autoregressively — one at a time, responding to your movement inputs, building up the world around you on the fly as you explore. Feed it one image or a text prompt and it produces a navigable environment in real time. The world extends and springs into existence as you move through it. Areas you don’t visit or turn to look at are never generated into existence.
This is not a pre-rendered video. It’s an AI model predicting in real time what is likely to be around the next corner based on the user’s movements and what it’s learned about how similar worlds look.
Google DeepMind Genie3 Output
The fidelity was high enough to be uncomfortable. For the first thirty seconds or so, the Dust Bowl scene felt spatially coherent with consistent lighting, plausible architecture, and realistic period detail. It degraded as I continued navigating, with textures softening and geometry losing confidence, but the initial impression was convincing enough that a casual viewer could easily mistake it for a real place.
Genie 3’s realism and believability are the problem. Nothing in the output distinguishes what came from the source photograph and what the model fabricated. There is no seam, no visual indicator, no metadata. The landscape to my left might have been derived from pixel data in the original image or it might have been entirely hallucinated from the model’s training set. I could tell the difference because I knew the photograph it had been prompted with, but without that knowledge it would have been impossible to tell the difference.
Compared to Apple’s SHARP, SHARP also generates a 3D scene from a single image, but SHARP’s output is strictly limited to the input photo and generates what is seen in the photo, except with added 3D depth. It’s possible to move around the scene, but the illusion breaks as soon as you step significantly outside the bounds of the input image. Genie 3 is doing something more radical: it’s continuing the world beyond the frame, inventing spaces the camera never saw. The result looks similar but the implications for trust are very different. SHARP augments a photo within the bounds of the origins image. Genie completely blasts through the edges of the photo.
Apple Sharp Output
Genie 3 is not a research demo anymore. It’s a product. And it’s not alone. Fei-Fei Li’s World Labs Marble shipped its commercial API and closed a $1 billion funding round. Tencent’s HunyuanWorld is an open source world model that gives anyone to create their own virtual worlds from prompts, but requires the user to have access to a computer with professional grade CPU, GPU, and memory. The capability to generate convincing, navigable 3D worlds from a flat image is now a commodity available to anyone with a credit card — or, in Tencent’s case, a commercial-grade GPU.
And none of these tools produce provenance metadata. There is no content credential attached to a Genie 3 world. No C2PA manifest. No indication of what was source material and what was synthesized. If someone records a walkthrough of a generated Dust Bowl scene and posts it without context, there is currently nothing in the file itself that would help a viewer, a journalist, or an archivist distinguish it from footage of a real place.
Genie 3 access currently requires a US location and a Google AI Ultra subscription ($250/month). Sessions cap at 60 seconds, though you can re-enter your world afterward. If you’d rather not pay, Odyssey has a free web demo worth exploring, and there are open-source options (HY-WorldPlay, lingbot-world) you can run locally.
The difference between 3D reconstructions of real spaces and AI generated plausible ones is getting harder to see from the outside. That’s why Starling Lab has been working on authenticity for emerging technologies including a “nutrition label” for synthetic media. World models like Genie 3 pose an even greater challenge when the output isn’t a single image but an entire explorable environment generated in real time, different for every user session, never the same twice.
Spatial Lab is a publication of Starling Lab, a joint initiative of Stanford University and USC focused on data integrity. We cover spatial intelligence technologies for journalism, law, and historical documentation.
Apple SHARP: When Any Photograph Becomes 3D
Spatial
I’ve been experimenting with 3D reconstruction from archival photographs for the past year at Spatial Lab, and when we started in early 2025, I wasn’t sure high-quality single-image-to-3D was even possible. Gradually I developed processes with diffusion models that created convincing 3D scenes from 2D images, but they were painstaking manual processes that took hours to complete. Now, with Apple’s SHARP, there is a fast, opensource, image-to-3D process freely available.
SHARP converted a single 1930s Dorothea Lange photograph I fed it into a three dimensional object in seconds. A flat image from the Library of Congress became something I could manipulate and view from different angles.
From a single photograph to 3D. No multi-angle capture or orbiting video required. For someone like me who is used to doing 3D capture with multi-camera rigs, capturing hundreds and sometimes tens of thousands of images to reconstruct scenes, this felt astonishing.
Apple SHARP output
In December, Apple released SHARP, which they describe as “photorealistic view synthesis from a single image.” A more practical description: it’s a 2D-to-3D depth extraction process that turns any photograph you feed it into a 3D scene. It works on a mobile phone photo shot today as well as it does on a hundred-year-old archival image.
The code is open, it runs on Mac, Linux, and Windows, and you can install it yourself or use the prepackaged version in Pinokio. If you’ve ever struggled to get a breakthrough research paper’s code running on your own machine, only to discover it requires an 8-GPU cluster and a terabyte of RAM, you’ll appreciate what Apple has done here. SHARP is genuinely accessible, and that matters because accessibility is what turns a research curiosity into an infrastructure problem. When anyone can do this, everyone will.
And everyone did. Shortly after its release, my LinkedIn feed and 3D Gaussian splat hosting sites like SuperSplat were flooded with SHARP outputs of photos of all kinds turned into 3D.
To be honest, at first I had mixed feelings about SHARP. While it does feel magical in the way it adds depth to 2D photos, the results are fairly limited. The resultant 3D is only really viewable a few degrees off center. After that, the limits of monocular depth extraction become obvious. Faces and objects are curiously squashed when viewed from the side, and the more you move away from the original viewpoint of the photo the more the reconstruction deteriorates. But within the limitations the results are truly sharp, retaining the photorealistic and crisp character of source images where diffusion model processes often turn mushy.
Part of me was also frustrated that the painstaking processes were now obsolete, and a unique capability I’d once enjoyed was now available to everyone and their dog at no effort. But that’s just life in a fast-moving discipline, I suppose.
Apple SHARP Limitations
SHARP doesn’t generate worlds. It doesn’t hallucinate scenery beyond the frame or fill in what the camera didn’t see. What it does is take the flat image you give it and infer depth: Deciding what’s in the foreground, what’s in the background, and the general shape of objects in the scene. The result is a 3D relief of the original photograph, not an environment you can walk through.
That sounds modest. But it sits at one end of a spectrum that extends to tools like World Labs’ Marble, Google’s Project Genie, and Tencent’s HunyuanWorld, which produce full 360° 3D environments from text and image prompts. At that end of the spectrum, the provenance question is blunt: how much of what I’m seeing exists in any source material at all? The answer, often, is very little.
SHARP’s provenance question is subtler, and in some ways harder. Every pixel you see in a SHARP output comes from the original photograph. Nothing has been added. But the spatial relationships between those pixels — what’s in front of what, how far apart objects are, the curvature of surfaces — are entirely inferred by the model. The image is real. The depth is a guess. And the guess is informed not by the photograph itself, but by the model’s understanding of how the world generally looks.
For cultural memory and education, this distinction might not matter much. A 3D rendering of a historical photograph that adds a sense of depth without fabricating content is a powerful tool for engagement. But for evidence and documentation, the distinction matters enormously. If a legal team presents a 3D reconstruction of a crime scene photograph, the jury needs to know that the spatial relationships they’re perceiving, such as which object was closer to which, whether a doorway was within reach, are inferences, not measurements. The image says “this is what was there.” The depth says “this is roughly where we think it was.” Those are different claims with different evidentiary weight.
What we observed. In our experiments converting archival photographs with SHARP, a few things stood out.
The depth estimation is more convincing than you’d expect, and that’s potentially a problem. When we converted FSA photographs from the 1930s, the results felt spatially plausible. Objects appeared to sit at reasonable distances from each other. Rooms had a sense of volume. But nothing in the output distinguishes estimated depth from measured depth. A viewer has no way of knowing whether the spatial arrangement they’re seeing reflects the actual scene or the model’s best guess about scenes that generally look like this.
Right now, SHARP’s own limitations provide a kind of accidental honesty when you move a few degrees off center and the illusion breaks, signaling the boundary between what the model knows and what it’s guessing. But it won’t always be this way. As monocular depth estimation improves, the artifacts will shrink, and the line between measured and inferred will become invisible. The time to build trust infrastructure is now, while the seams are still showing.
And regardless of how good the depth estimation gets, metadata doesn’t survive the conversion. A photograph with C2PA content credentials enters the SHARP pipeline; what exits is a 3D object with no connection to the original provenance chain.
SHARP monocular depth detail
The spectrum from monocular depth estimation to full world generation is filling in fast, and the provenance challenges are different at each point. For SHARP, the question is: are the spatial relationships documented or inferred? For world models, the question is: how much of this environment exists in any source material at all? Both need answers, and both need different labels.
At Spatial Lab we’re working on a provenance layer that persists through reconstruction, for any given 3D creation spelling out what the inputs were and what processes and transformations occurred. We’ve been prototyping what we call a “nutrition label” for synthetic media, and the need for it just became a lot more urgent.
If you’re working with archival photographs, spatial documentation, or digital evidence and grappling with these questions, we’d like to hear from you — especially if you’ve tried to maintain provenance through a 3D reconstruction pipeline. Reach out at info@starlinglab.org.
Spatial Lab is a publication of Starling Lab, a joint initiative of Stanford University and USC focused on data integrity. We cover spatial intelligence technologies for journalism, law, and historical documentation.

What Should a Nutrition Label for Synthetic Media Say?
Spatial
Imagine pouring a bowl of cereal, grabbing a spoon, and getting ready to read the back of the box while you eat (there is no finer literary experience). You’d be surprised if there was no nutritional information, no indication of whether it’s organic, made from whole grains, or comes with 5 kinds of ‘magically delicious’ marshmallows. That’s essentially where we are with AI-generated and AI-enhanced imagery today.
At Starling Lab, we’ve been prototyping what we call a “nutrition label” for synthetic media, intended to be a standardized way of communicating what audiences are actually looking at. After months of experiments and dead ends, here’s where our thinking has landed.
The problem we’re addressing is when someone views a 3D reconstruction or an AI-enhanced photograph, they have no way of knowing:
What source material was used, how much of what they see is captured vs. AI generated, what tools and processes created the output, and who made key decisions and when.
This information exists but it’s not revealed to the viewer.
Our goal isn’t to make everything look suspicious or to undermine the enjoyment of immersive experiences. It’s to give audiences the information they need to evaluate what they’re seeing. A 3D reconstruction based on 500 authenticated photographs of a real-world scene would likely mean something different to an audience than one generated from a single image and creative prompting, or even no source image at all.
We’ve identified five categories of information we think a nutrition label should include.
Source Summary: How many source assets? What types (photo, video, LiDAR)? What percentage of the output is directly derived from source material vs. interpolated/generated?
Example: “Based on 47 photographs. Approximately 60% of visible content derives from source imagery.”
Generation Disclosure: Were generative AI tools used? For what purpose? This isn’t about banning AI—it’s about transparency.
Example: “Depth estimation enhanced with AI. No content generation tools used.” Or: “Scene extended beyond source frames using diffusion model.”
Provenance Chain: Can the source material be authenticated? Is there a cryptographic trail linking this output to verified originals?
Example: “Source images authenticated via C2PA. Verification available.” [Link]
Modification History: Has this asset been edited since initial creation? By whom? When?
Example: “No modifications since initial processing. Created: March 15, 2025.”
Confidence Indicators: For spatial reconstructions, where is the model confident and where is it uncertain? This might be communicated visually rather than textually.
Example: “Areas in blue overlay indicate lower reconstruction confidence.”
Listing this information is easy. Designing a UX to present it without killing the experience is hard. Nobody wants to read a paragraph of metadata before exploring a 3D scene reconstruction. But that information needs to be accessible for people who want or need to know.
Our proposed approach uses layers to accommodate both casual viewers who just want the experience and careful consumers who need verification.
- At-a-glance indicators: A simple badge or border color that communicates overall trust level. Green for fully authenticated source material with no generation. Yellow for mixed. Red for significant generation or unknown provenance.
- One-tap summary: A single tap reveals the five categories above in readable prose.
- Full provenance: For experts who want to dig deeper, the complete cryptographic record is accessible—every hash, every signature, every registered ledger entry.

Creating this label has forced us to confront questions we don’t yet have clean answers to.
The most fundamental is where the line falls between enhancement and generation. If I use AI to sharpen a blurry photograph, most people would call that enhancement. If I use AI to generate an entirely new scene from a text prompt, most people would call that generation. But the interesting cases live in between, and they’re the ones that matter most for spatial media. AI-assisted depth estimation—the technique that tools like Apple’s SHARP use to infer 3D structure from a flat image—doesn’t add any pixels. Every pixel in the output comes from the original photograph. But the spatial relationships between those pixels are entirely inferred by a model. Is that enhancement or generation? Reasonable people disagree, and the answer probably depends on what the output is being used for. A museum exhibit and a courtroom presentation have different stakes.
Then there’s the question of thresholds. Should every automated process be listed, or only those above some significance level? Who defines “significant”? A depth estimation step that’s invisible to a casual viewer might be the single most important piece of information for an investigator trying to assess whether a spatial reconstruction reflects ground truth. We haven’t solved this. Our current approach is to disclose everything and let the layered UI handle the complexity, but that pushes the problem to the UX layer rather than resolving it.
A voluntary label is only useful if it’s adopted. We’re working with industry partners, but there’s no central authority that can mandate compliance. And right now, the organizations most likely to adopt transparent labeling are the ones that least need it – institutions already committed to accuracy. Nothing stops bad actors from falsely labeling fabricated content as authentic. The label creates accountability for those who use it honestly; it doesn’t prevent deception by those who don’t.
We’ve built a working prototype that embeds this information in ComfyUI AI outputs as well as Gaussian splat files and surfaces it in web-based viewers. Some things work. The metadata embedding itself is straightforward—C2PA content credentials can carry all five categories of information, and our pipeline successfully writes and reads them. The layered UI concept holds up: test users consistently ignored the at-a-glance badge until they wanted it, which is exactly the behavior we were designing for.
Other things don’t work yet. Our visual indicators showing where a reconstruction is certain vs. uncertain are crude. They communicate the concept but they’re not production-quality, and the visual language for “this area is less reliable” hasn’t been solved by anyone. More fundamentally, the label doesn’t survive format conversion. Export a labeled Gaussian splat to a video for social media and the provenance data is stripped. That’s not a bug in our prototype; it’s a gap in the ecosystem.
Our UX is imperfect but it demonstrates that provenance information can travel with spatial media the same way ingredient lists travel with packaged food. If you’re working on similar problems, whether in content authenticity, spatial computing, or UX for trust signals, we’d like to hear from you.
Spatial Lab is a publication of Starling Lab, a joint initiative of Stanford University and USC focused on data integrity. We cover spatial intelligence technologies for journalism, law, and historical documentation.
The Post-Photographic Age Is Here. What Does That Mean for Trust?
Spatial
For over 180 years, photographs have served as evidence. A photograph was understood to be a mechanical recording of light that existed in a specific place at a specific time. In other words, proof of the existence of an object or event. This evidentiary assumption underpins journalism, law enforcement, insurance claims, scientific research, and countless other domains. With the advent of AI-generated synthetic imagery, that assumption is now obsolete.
This is not a new problem. Photography itself was once a disruptive technology. Before cameras, courtroom evidence was testimony and physical objects. Early photographs faced skepticism. Could they be trusted? Were they accurate? Over decades, societies developed frameworks: chains of custody, expert authentication, standards for admissibility. We’re at a similar inflection point now.
Today’s emerging technologies have different names — Gaussian splatting, Neural Radiance Fields, diffusion models, world models — but they share a common capability: they can create imagery that never existed. What makes this moment different is that it has made obvious how fragile our systems of trust and authenticity have always been.
A radience field and its underlying pointcloud
Previous advances in image manipulation, such as darkroom techniques, Photoshop, CGI special effects were detectable by experts, and producing convincing fraudulent images required significant skill, effort, and time. Well-made forgeries were expensive, rare, and could still be debunked by people who knew what to look for.
Today’s tools are different in four ways:
Accessibility. Creating photorealistic synthetic content no longer requires expertise or significant resources. Consumer apps and cloud services can do it for pennies. Students with no graphics background are creating immersive 3D environments in minutes.
Quality. The outputs are becoming indistinguishable from reality. Not “good enough to fool casual observers,” but actually indistinguishable from the real thing.
Volume. Creating a thousand fakes is just as easy as creating one. A single bad actor can overwhelm society’s ability to detect and debunk in a timely manner, defeating fact checking by sheer volume. Once a fraud has spread on social media, the damage is done.
Blending. This is the shift that doesn’t get enough attention, and it’s the one that concerns us most. The most challenging content isn’t purely synthetic — it’s hybrid. Real captures algorithmically extended. Authentic photographs turned into explorable 3D scenes. Genuine footage enhanced with generated elements. Where does documentation end and fabrication begin? At what point does an immersive 3D experience based upon a single photo cease to inform and begin to mislead?
In our own experiments at Spatial Lab, we’ve encountered this boundary directly. When we used World Lab’s Marble to convert a 1940s photograph of a scene of the forced detention of Japanese Americans into a 3D environment, the result was stunning — and deeply ambiguous. The original photograph anchored the scene, but the model filled in buildings and landscape, and inferred objects that were never captured. To a viewer navigating the space, every surface looked equally real. Nothing in the experience distinguished what was documented from what was hallucinated.
This isn’t a failure of the technology. It’s working as designed. But it’s a problem that we currently have no widely adopted means to know whether what we are looking at is real.
The same technologies that threaten trust also offer unprecedented capabilities for understanding. A journalist with Gaussian splatting can show audiences a disaster scene in three dimensions, letting them understand spatial relationships that flat photographs obscure. A historian can transform a single archival image into an explorable environment, bringing the past alive in ways previously impossible. A prosecutor can reconstruct a crime scene from authenticated source material, letting jurors experience spatial context that flat images cannot convey.
These are genuinely valuable uses. They serve truth, not deception — if we can establish that the underlying sources are authentic and the reconstruction process is faithful to the source and transparent.
At Spatial Lab, we believe the post-photographic age can be navigated successfully. But only if we build the infrastructure now. That means:
Cryptographic provenance for source material. Before any reconstruction begins, the input imagery should be authenticated. Where was it captured? When? By whom? This creates a root of trust that can flow through the entire pipeline. Distributed ledgers are well-suited for this — they produce easily verifiable, public, unalterable, and permanent records.
Transparency about reconstruction processes. Audiences need to know what tools were used, what choices were made, and where algorithmic interpolation occurred. Not buried in technical metadata — surfaced in the experience itself. We’re prototyping what we call a “nutrition label” for synthetic media: a standardized way to communicate the ingredients of a spatial experience.
A visual language for uncertainty. In traditional media, the boundary between the known and the unknown is implicit. Photographs have borders where the image ends. Videos have a beginning and end. We understand that beyond the frame, there is a world we have no information about. AI-generated content is different. The source image is a jumping-off point from which the technology can endlessly generate beyond the original frame. But to the viewer, both the ground-truth image and the AI-hallucinated extension appear equally real.
We’re researching ways to show audiences, in real time, the boundary between captured reality and generated content — UX overlays that apply color, blur, or other visual cues to signal uncertainty while maintaining both immersion and honesty. The tools have to be built first.
Spatial Lab exists to do this research in public — to share experiments, invite debate, and prototype solutions. We’re an academic initiative at the intersection of Stanford and USC, not a company selling products. Our goal is to develop frameworks that anyone can implement.
If you’re working on similar problems, we want to talk. If you think we’re wrong about something, we want to hear why. If you’re from an industry that will be affected by these changes, we want to understand your concerns.
The post-photographic age arrived faster than anyone expected. The frameworks for trust can still be built. This is an invitation to help build them.
Spatial Lab is a publication of Starling Lab, a joint initiative of Stanford University and USC focused on data integrity. We cover spatial intelligence technologies for journalism, law, and historical documentation.