Preserving Harvard Public Health on the Distributed Web

Store
In late February 2025, Harvard Public Health magazine announced it was shutting down. Editor-in-chief Michael F. Fitzgerald delivered the news plainly: journalism is expensive and outside of a university’s core mission of teaching and research. The magazine, which had relaunched as a digital-first publication and tripled its readership in the final year, ran out of time to build sustainable revenue streams.
The closure is another casualty in the ongoing challenge of funding quality public health journalism. Harvard Public Health had covered topics ranging from the Flint water crisis to processed foods, mental health, and structural racism – work that won recognition and built an audience of nearly 15,000 newsletter subscribers, 90 percent of whom had no connection to Harvard.
Fitzgerald encouraged readers to download articles they found useful before the site eventually goes dark. But individual downloads are an imperfect solution for preserving a decade’s worth of public health journalism. The question became: how do we ensure this body of work remains accessible to researchers, public health professionals, and the public long after Harvard stops paying the hosting bills?
The Distributed Press Clone API
Distributed Press is an open-source publishing tool developed by Hypha Worker Co-operative and Sutty Coop that automates publishing and hosting content to both the traditional web and decentralized protocols like IPFS and Hypercore. Where traditional web hosting depends on a single provider, distributed networks allow anyone to help co-host content – making it resilient against the kind of institutional decisions that led to Harvard Public Health’s closure.
The recently launched Clone API makes this preservation process remarkably straightforward. Rather than manually downloading and re-uploading thousands of pages, the API can crawl an entire website and publish it directly to IPFS and Hypercore.
The entire preservation took three API calls and about an hour of automated crawling.
Technical Walkthrough
Here are the steps to preserve a website using the Distributed Press Clone API:
Step 1: Obtain API Access
Distributed Press requires an authorization token. Instructions for requesting access are available at distributed.press/2024/10/18/get-a-token/. Once obtained, the token is entered into the Distributed Press API Swagger interface.
Step 2: Create a Site Configuration
Using the API, create a new site with the target domain (harvardpublichealth.org) in the configuration bundle. This tells Distributed Press which domain to crawl and how to structure the resulting archive.
Step 3: Initiate the Clone
Call the Clone API endpoint to begin crawling. The system works in the background, following links and downloading assets. For a site the size of Harvard Public Health, this takes approximately one hour.
Step 4: Query Site Information
Once complete, query the site information to retrieve the archive’s addresses on both protocols. The API returns a JSON response containing the IPFS CID (Content Identifier), Hypercore key, and various gateway URLs.
Accessing the Archive
The preserved Harvard Public Health site is now available at two permanent addresses:
IPFS:
bafybeihg5mdtwrfa4ywm4orsloojvysuaurr36p57tlwshydv2rgbxws5a
Accessible via gateway:
https://bafybeihg5mdtwrfa4ywm4orsloojvysuaurr36p57tlwshydv2rgbxws5a.ipfs.ipfs.hypha.coop/
The IPFS CID is a cryptographic hash of the content itself. As long as anyone on the IPFS network continues to pin this CID, the content remains accessible – regardless of what happens to Harvard’s servers. The same principle applies to the Hypercore key. These addresses are permanent: they will always point to this exact version of the site.
Why This Matters
Web content is fragile. Studies have found that the average lifespan of a webpage is measured in years, not decades. Institutional priorities shift, budgets get cut, and valuable archives disappear without warning. The Harvard Public Health closure is a textbook case: the institution decided journalism wasn’t core to its mission, and a decade of public health reporting became an orphan.
Traditional archiving solutions like the Internet Archive’s Wayback Machine provide important preservation, but they operate as centralized services with their own resource constraints and priorities. Distributed protocols offer a complementary approach where preservation becomes a collective responsibility. Anyone who values this content can pin it to their own IPFS node, helping ensure it remains available.
For researchers and public health professionals, this archive preserves not just individual articles but the navigational structure of the original site – the way topics were organized, the relationships between pieces, and the editorial voice that connected them. That contextual integrity is often lost when content is scattered across individual downloads or incomplete archive snapshots.
Replicating This Process
Organizations with valuable web archives, whether facing shutdown or simply wanting redundant preservation, can use this same approach. The process requires:
- An account with Distributed Press (contact the team for access)
- A domain configuration for the target site
- Sufficient time for the crawl to complete
The resulting archives can be pinned by anyone with an IPFS node or Hypercore peer, distributing the preservation responsibility across multiple parties and jurisdictions.
For those interested in the technical implementation, the Distributed Press documentation is available at docs.distributed.press, and the Clone API is documented in the API reference.
Next Steps
This preservation effort was initiated independently by Hypha, but demonstrates a workflow that could be systematically applied to at-risk publications. As journalism continues to face financial pressures, having fast, reliable tools for distributed archiving becomes increasingly important.
We encourage institutions facing similar closures to consider distributed preservation as part of their wind-down planning. We also encourage researchers and archivists to pin this CID and contribute to the network of peers keeping Harvard Public Health’s journalism accessible.
If you have questions about applying these techniques to your own preservation needs, reach out to the Distributed Press team via their documentation site, or contact Starling Lab at info@starlinglab.org.
This project was documented by Hypha Worker Co-operative. The preservation was completed using the Distributed Press Clone API on March 4, 2025.

Safeguarding History: Preserving Armenian Cultural Heritage on the Decentralized Web

Store
Our mission is to securely capture, store, and verify the world’s most vulnerable digital records. Today, we are proud to announce a significant milestone in that mission: the successful preservation of several terabytes of critical data from the TUMO and Armenian Cultural Heritage Institute’s Scanning Project. This data is now securely stored at the USC Digital Repository, part of the USC Libraries – our academic co-anchor.
This collaboration represents more than just data storage: it is a vital effort to protect cultural memory in the face of conflict and erasure.
Preserving “Digital Twins” of Endangered Sites
The data we have preserved consists of high-fidelity 3D scans – including photogrammetry and laser scan data – of Armenian cultural heritage sites located in the Artsakh (Nagorno-Karabakh) region. The collection includes original raw photographs and 3D models of monasteries, churches, and monuments, many of which are currently inaccessible or at risk of destruction due ethnic cleansing policies carried out by Azerbaijani authorities in the region (see EU Parliament resolution and Caucasus Heritage Watch at Cornell University for more).
By creating and preserving these “digital twins,” TUMO, Armenian Cultural Heritage Institute and Starling Lab are ensuring that even if the physical sites are damaged or erased, accurate and immersive records will survive for future generations of historians, researchers, and the public. This initiative directly counters the threat of cultural erasure by creating an immutable, decentralized record of this heritage.
Powered by World-Class Preservation Infrastructure
To ensure these records are resilient against censorship, data loss, and single points of failure, we have stored them on the USC Filecoin Node.
More than a simple server, this node is in fact a massive 22-petabyte storage facility integrated into both the USC Digital Repository and the Filecoin network. It leverages cryptographic proofs to guarantee data durability while offering the immense scale required for high-fidelity 3D historical archives.

It is operated by us at Starling Lab and the USC Digital Repository, a service of the USC Libraries. While the Filecoin node represents the cutting edge of decentralized storage, it is just one part of the Libraries’ deep expertise in preservation and archiving. By housing this node within a leading research university, we combine the innovation of Web3 protocols with the rigorous preservation standards developed over decades by archivists and librarians.
We have committed to preserving this archive for 20 years, ensuring that the history of Armenian heritage in Artsakh (Nagorno-Karabakh) remains accessible in the long term – at no cost to TUMO, the custodians of that archive.
The Frontier of Spatial Intelligence
This preservation effort also dovetails with our broader research into 3D and spatial intelligence. As we move beyond 2D images, technologies like Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting allow us to transform standard photographs into fully immersive, navigable 3D environments.
By applying our “Authenticity by Design” framework to these 3D datasets, we are not just storing files; we are establishing a root of trust for spatial experiences. This allows us to verify that a 3D reconstruction of a heritage site is faithful to the original scans and has not been manipulated. As we continue to develop these tools, the TUMO collection will serve as a foundational dataset for testing how we can authenticate and experience history in the metaverse.
Preserving such a collection is a powerful demonstration of how decentralized technology can serve humanity. By locking these records on the blockchain, we are ensuring that the history of Armenian heritage in Artsakh (Nagorno-Karabakh) can never be deleted, denied, or forgotten.
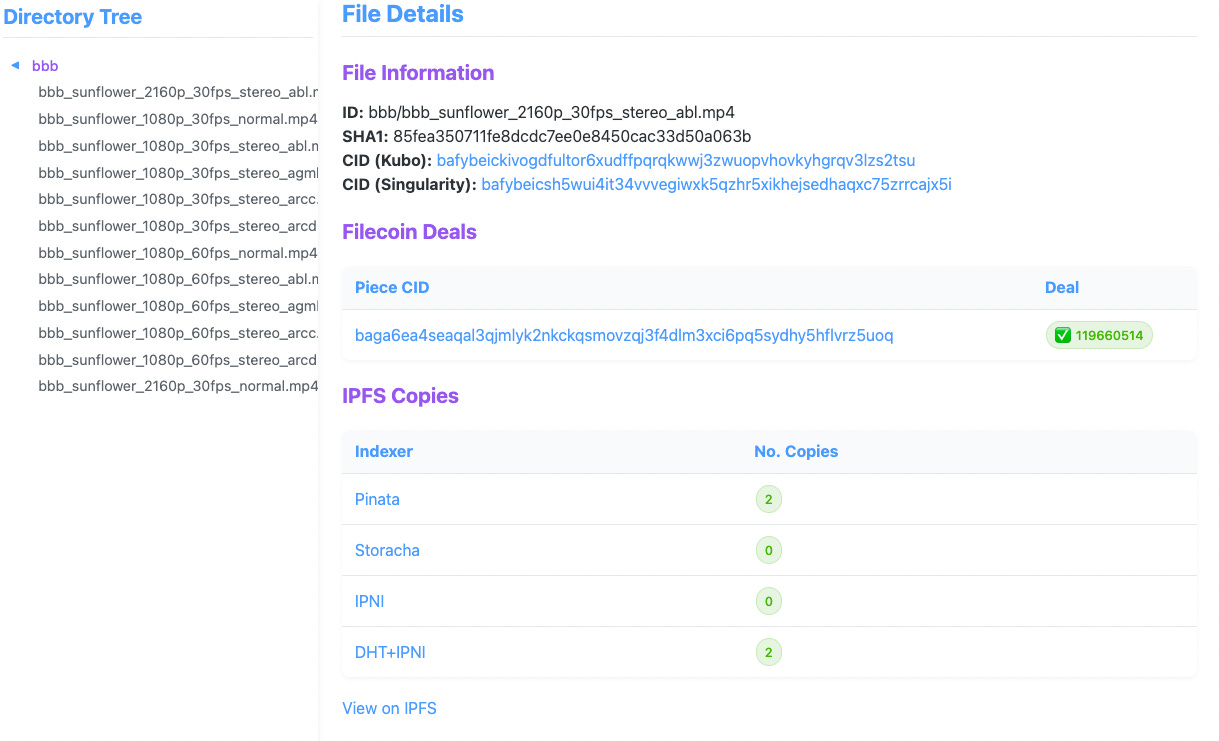
Finding Your Files in Decentralized Storage Just Got Easier
Store
At Starling Lab, we’re dedicated to building tools that empower secure and verifiable data storage. Today, we’re thrilled to announce the CAR Content Locator, a tool originally developed to support our Filecoin archiving work at the USC Digital Repository. With support from the IPFS Implementations Grants program, we’ve evolved this browser-based tool beyond its original purpose – tracking private files on the USC Filecoin node – into a general-purpose content locator across Filecoin and IPFS networks.
Why We Built the CAR Content Locator
As decentralized storage solutions become more prevalent, the need for robust, user-friendly tools to manage and verify content availability is critical. Our work with the USC Digital Repository highlighted a significant challenge: tracking individual files within CAR files (Content Addressable aRchives) and verifying their continued preservation without relying on public indexing services.
Organizations storing large datasets on Filecoin and IPFS face a practical problem: once dozens of files are bundled into CAR archives, how do you later find and verify specific ones?
Existing public indexing services can’t help with private or institutional data, and unfortunately our work with the USC Digital Repository – which looks after 1.2PiB+ of private archives – highlighted this challenge.
This led us to develop a tool that:
- Maps file CIDs (Content Identifiers) to their locations within CAR files, especially when CAR metadata and file data exist in separate CAR files.
- Extracts specific files using either a file identifier or CID across multiple CAR files.
- Connects Piece CIDs and Deal IDs on the Filecoin network without requiring a full indexer.
Feature Highlights
The CAR Content Locator codebase is now published on GitHub under the MIT License, and can easily be deployed using Docker Compose. It features:
- A web-based file browser that displays file integrity information (i.e. CIDs) and their availability across Filecoin and IPFS networks;
- For Filecoin storage information, a Singularity-based workflow is required as it relies on its databases to keep track of Piece and Deal information;
- For IPFS content availability, the tool relies on delegated routing endpoints to be available;
- Although the tool is preconfigured with several public indexers, such as Pinata and Storacha, it also supports private IPFS networks, and similarly, private Filecoin nodes with the required Singularity databases.
Explore the tool in action at our demo instance!
Learnings & Next Steps
During development of the CAR Content Locator, we also conducted research on how different organizations – particularly those managing large datasets like the USC Digital Repository – address similar use cases for tracking their files across CAR-compatible networks.
We found little consistency in how users interact with Filecoin and IPFS, and workflows and toolings are usually bespoke and tailored to specific organizational needs. We hope that publishing this open source tool will also participate to the conversation on building common tooling across similar organizations.
We’d greatly appreciate your input:
- Share with us how your organization tracks files stored on Filecoin and/or IPFS;
- File tickets on starlinglab/car-content-locator on what features would make this tool helpful to you.
The CAR Content Locator’s development has been significantly shaped by the specific needs of the USC Libraries, and it continues to keep track of its 1.2 PiB+ of private archives on their Filecoin node. Our team also works closely in parallel with the Internet Archive’ Filecoin operations.
This work is made possible by the Open Impact Foundation and the Filecoin Foundation for the Decentralized Web, as well as those who advised / contributed feedback: Mosh, Robin, Bumblefudge, Lidel, Arkadiy, Casey, Sankara, Ian, and the whole USC Digital Repository and Libraries team.

Evidence Collection & Consent

Store

A verifiable ingestion framework designed to transform multimedia submissions from secure messaging apps into court-admissible evidence.
By integrating decentralized chatbots with platforms like Signal and Telegram, it establishes a tamper-evident chain of custody that cryptographically binds media to the explicit, informed consent of the source.
This approach bridges the gap between high-risk field documentation and the rigorous evidentiary standards of international justice mechanisms, ensuring that humanity’s most critical records remain legally robust and ethically sound.
YEAR
2022
PARTNERS
Guardian Project
ProofMode app
Signal
Telegram
The Problem
Digital media captured in high-stakes environments, such as war zones or human rights crises, may be required to meet the evidentiary standards required for criminal trials. While photos and videos are persuasive, they often lack a verifiable “chain of custody”. Traditional messaging services routinely strip critical metadata to protect privacy; however, this decontextualization makes it nearly impossible for investigators to prove origin or authenticity once the file leaves the original device.
Furthermore, without documented, informed consent from the source, such records are often deemed inadmissible, leaving critical survivor testimonies legally invisible.
The Solution
Starling developed a chatbot, integrating with secure messaging services like Signal and Telegram, to automate the authenticated collection of digital evidence. When a source sends media to the bot, the system instantly generates a cryptographic fingerprint (SHA-256 hash) and seals the file alongside its associated metadata in a tamper-evident archive.
Crucially, the bot leads the documenter through an interactive back-and-forth to record the informed consent of the sender at the moment of ingestion. This consent is cryptographically bound to the media’s unique hash, creating an immutable record of usage permissions. This authentication layer ensures that crowdsourced evidence can be prioritized, processed, and examined by international prosecutors with its legal and ethical integrity fully intact.
GOING FURTHER
Case Study: Building ProofMode as a Library in a custom, bespoke Signal build
Authenticated Change Tracking
Store

We integrate cryptographic provenance into the newsroom’s editorial lifecycle, ensuring that every modification – from photo edits to caption and metadata updates – is recorded in a verifiable, append-only log. By retrofitting existing Content Management Systems (CMS) with an authentication layer, newsrooms can provide an unalterable “audit trail” of their reporting process.
This shifts the trust model from static files to a dynamic, tamper-evident lineage, restoring transparency to the news-gathering and publishing workflow.
YEAR
2022-25
PARTNERS
Reuters
Hypha Coop
Fotoware
LINKS
– Case study: End-to-end authentication at Reuters from Canon cameras
– On displaying this metadata with Four Corners and Wordpress
The Problem
Modern newsroom Content Management Systems (CMS) are designed for efficiency, and can be improved to provide more evidentiary rigor. While they track changes internally, these records are stored in private, centralized databases that are vulnerable to tampering and opaque to the public. As stories evolve from raw field captures to published articles, critical metadata (like original capture time or source identity) is often lost or stripped during the editing process.
This creates a “black box” that prevents audiences from verifying the reporting’s journey and leaves journalists unable to defend their work against claims of post-capture manipulation.
The Solution
Starling is working to understand the existing tools that newsrooms use to ingest information and to write and edit their stories, and we are working to integrate the ability to better track and authenticate changelogs of images, text, and other documents. Our goal is to improve the ability of newsrooms to work on authenticated information, and add authentication to changes they make, within their existing content management systems.
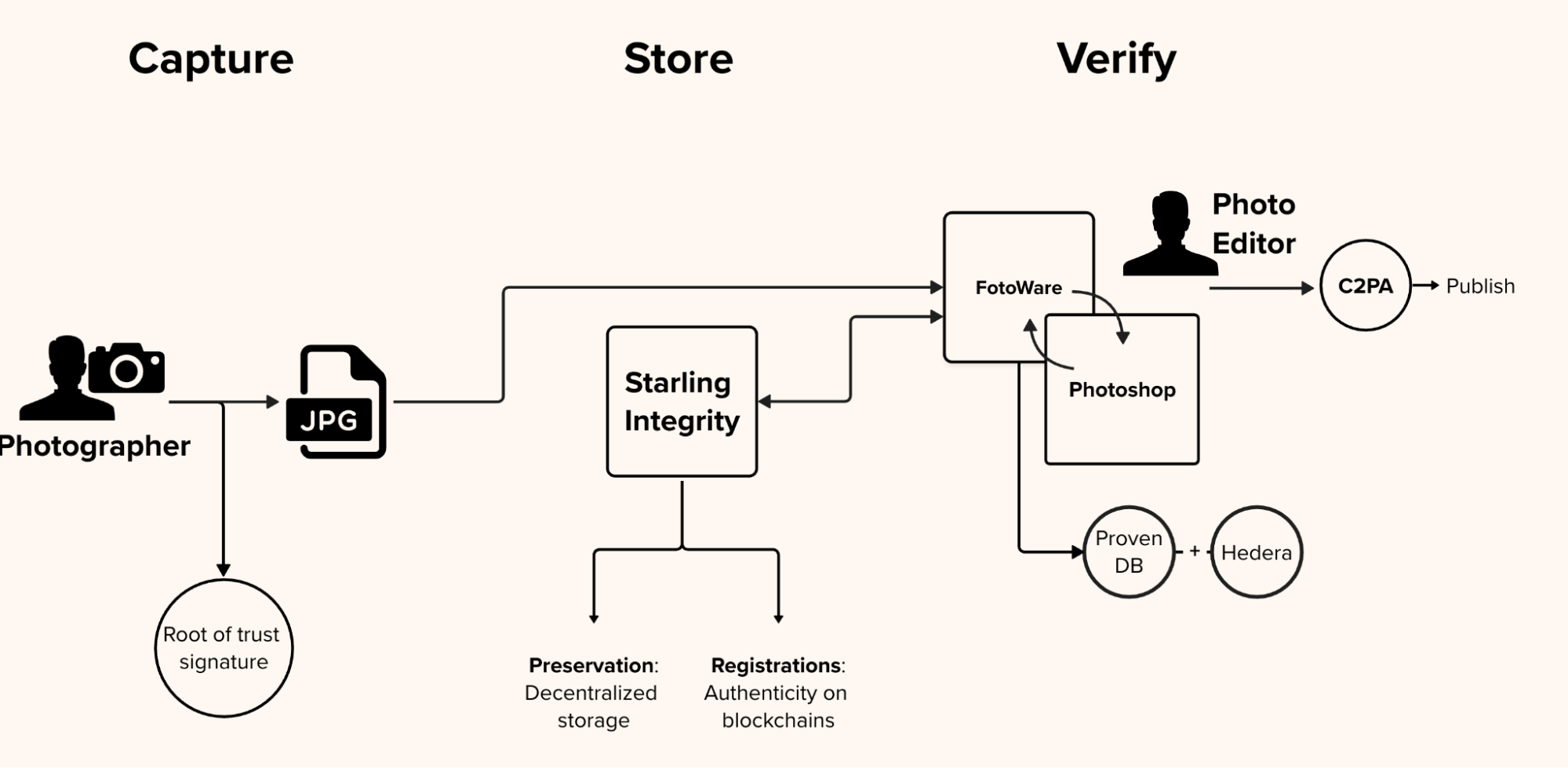
In the diagram above, CMS and Photoshop work in tandem so that the photographs’ edit history in Photoshop be reflected inside the CMS. In our milestone collaboration with Canon Camera and Reuters News, we designed a system that creates an immutable audit trail that works invisibly alongside standard newsroom tools. As the image is transmitted to the publisher’s asset management system and undergoes permissible edits by photo editors—such as cropping, color correction, or captioning—an automated background process tracks the file. Every single modification is recorded in a private, verifiable database that is anchored to a public distributed ledger, creating a mathematically provable edit log.
We are also prototyping how this information can be displayed to audiences, and looking for a greater understanding of what these metadata markers might mean to readers and the trust they place in stories and media. This final step focuses on empowering the end consumer: the reader. The prototype packages the initial hardware signature, the original metadata, and the complete, cryptographically secure edit history into a standardized, open-source manifest. This manifest is embedded directly into the final published image, allowing anyone—from researchers to everyday readers—to inspect the file and independently verify its authentic journey from the frontlines to their screen.

Distributed Storage

Store
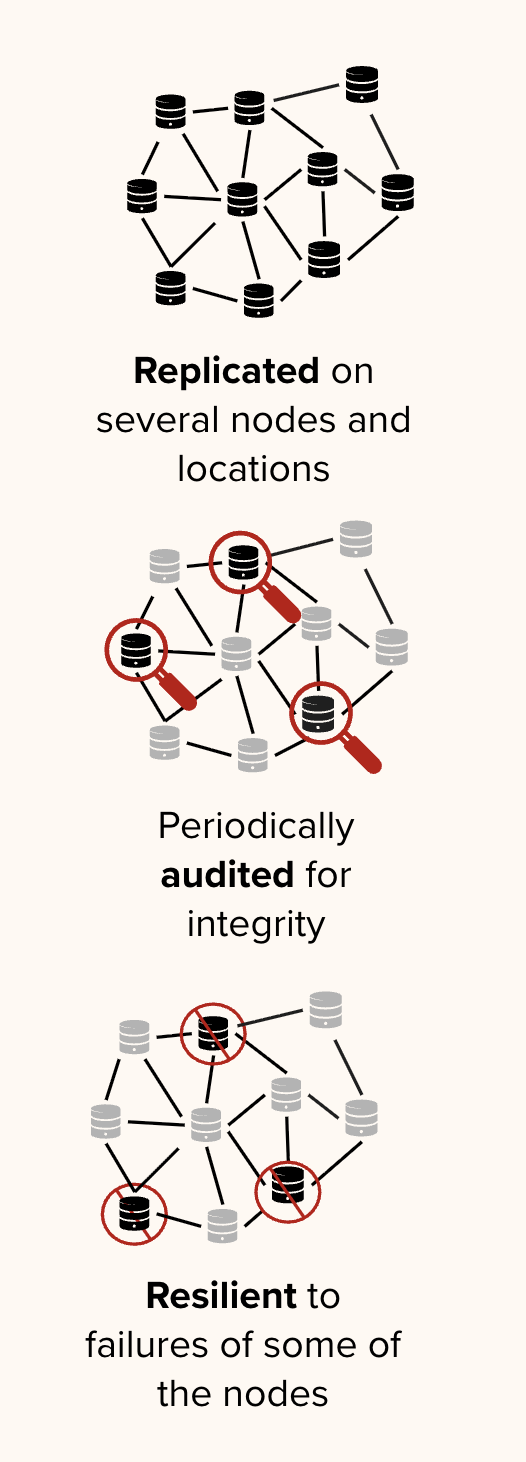
A decentralized infrastructure designed to ensure the long-term persistence and auditability of digital records by stripping centralized platforms of their outsized control over information.
Moving beyond fragile cloud silos, it cryptographically seals media and metadata across independent, multi-jurisdictional networks .
This framework shifts the preservation paradigm from blind trust in a single provider to a “proof of existence” model, where automated audits continuously verify that data remains untampered, replicated, and accessible .
YEAR
2021-25
PARTNERS
Filecoin
IPFS
Storacha
USC Libraries
The Problem
Traditional storage models rely on centralized cloud providers and social media platforms that exercise absolute authority over the availability and integrity of digital content. This creates a single point of failure: critical historical records can be silently modified, deleted due to shifting terms of service, or lost in jurisdictional disputes.
Standard databases also lack the transparency required for “chain-of-custody” documentation, making it difficult for archivists to prove that a file has not been altered since its initial preservation .
LINKS
– Case Study: Preserving 70 Years of Testimony with the USC Shoah Foundation
– Preserving Armenian Cultural Heritage on the Decentralized Web
– “Mom, I See War”, a collection of drawings from Ukrainian children, preserved on decentralised storage
The Solution
Starling Lab leads the world’s first academic center dedicated to using decentralized tools to advance human rights, backed by a multi-million dollar commitment from Protocol Labs and the Filecoin Foundation. We have moved beyond theoretical prototypes to large-scale implementations that safeguard humanity’s most sensitive digital records.
Our collaboration with the USC Shoah Foundation permanently preserves an archive of 55,000 video testimonies from genocide survivors. In tandem with the USC Digital Repository, a service of the USC Libraries, we run a 22-petabyte Filecoin node at USC – just one part of the Libraries’ deep expertise in preservation and archiving.
By housing this node within a leading research university, we combine the innovation of Web3 protocols with the rigorous preservation standards developed over decades by archivists and librarians.
Mom, I See War: A Digital Archive by Numbers Protocol and Starling Lab
Store
Mom, I See War (MISW) is the first known digital archive to document the way children experience war by preserving high-resolution jpeg scans of their drawings, metadata about the drawings, and encrypted versions of these that contain private, identifying information (the last names) of the children. MISW has a collection of 10,026 single-image assets from Russia’s invasion of Ukraine which Starling Lab has registered on the NEAR blockchain and archived on distributed web protocols.
- First, records of these assets were hashed and registered on the NEAR blockchain using Numbers Protocol.
- Second, versions of these drawings and separate metadata files (with the full names of the children redacted) were stored on IPFS.
- Copies of the metadata were injected with information according to the C2PA standards, which enables users to inspect and understand more about what’s been done to these records, where it’s been, and who’s responsible.
- An encrypted archive of the drawings (assets) and full metadata were also sealed and preserved as archives on Filecoin.
The four versions of records of these assets each serve a different purpose. The registration of a hash (or an immutable ‘fingerprint’ of the drawing and metadata) on the NEAR blockchain networks establishes a record of exactly what was stored, and a date that it was stored on, without revealing any other information.
The publication of the full drawings and metadata on IPFS (without individual identifying information like the last name of the child who made the drawing) makes these assets available on a publicly owned, peer-to-peer system which is resilient against infrastructure deprecation and various forms of censorship, and the assets can easily be hosted by anyone.
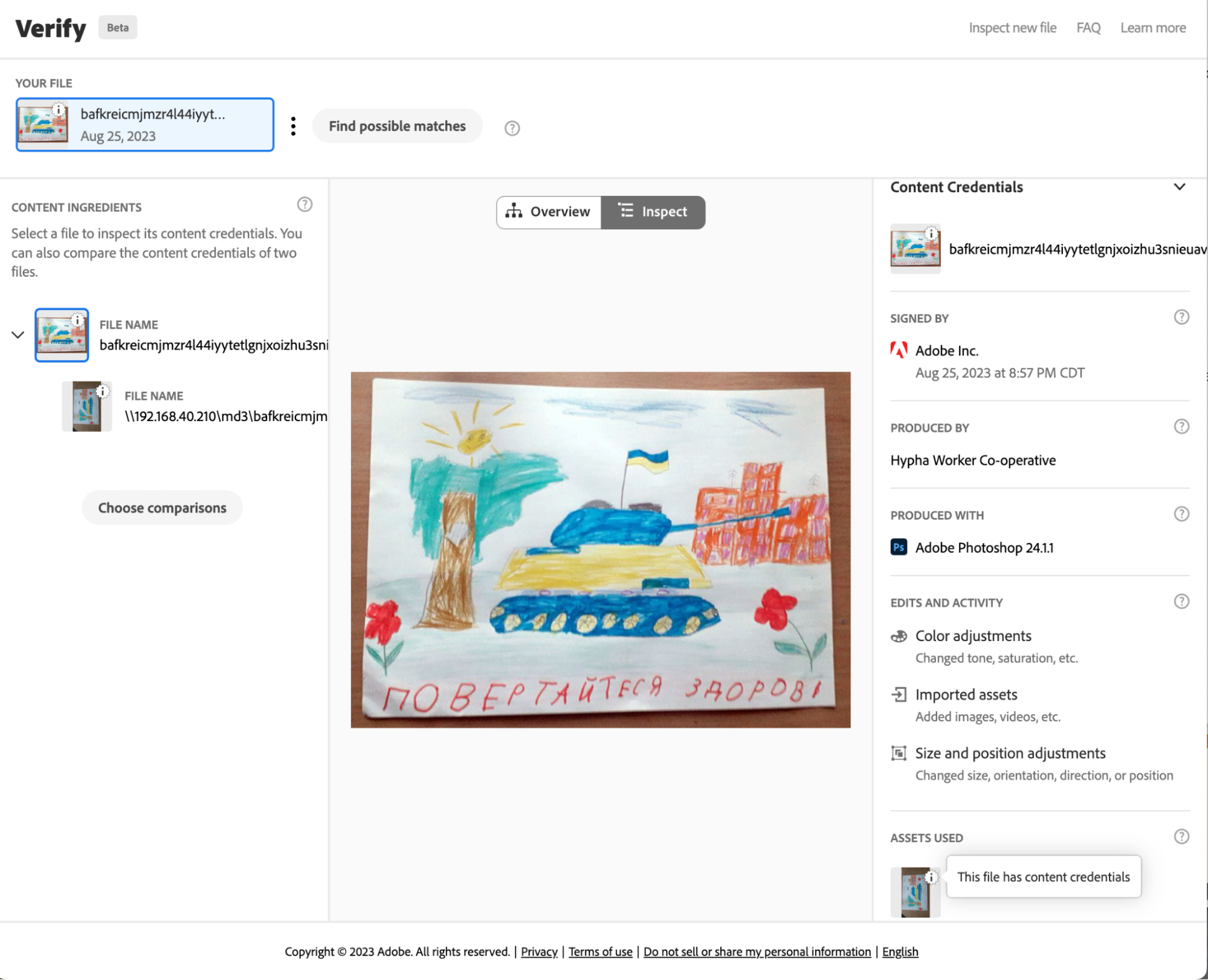
The C2PA version of the registered assets was created according to standards set by a coalition for standards development: The Coalition for Content Provenance and Authenticity (C2PA). These standards guide the development of tools, supported within Adobe products such as Photoshop, that create public and tamper-evident records that can be attached to an image. These images can then be used with different tools for inspecting and making edits that preserve the understanding of what’s been done to modify assets, where it’s been, and who’s responsible.
Finally, the archiving on Filecoin (drawings are bundled with full metadata and encrypted) helps preserve these drawings across multiple storage providers in a way that can outlast current media storage and publishing methods and technology.
Numbers Protocol Registration
Drawing & Metadata Registration
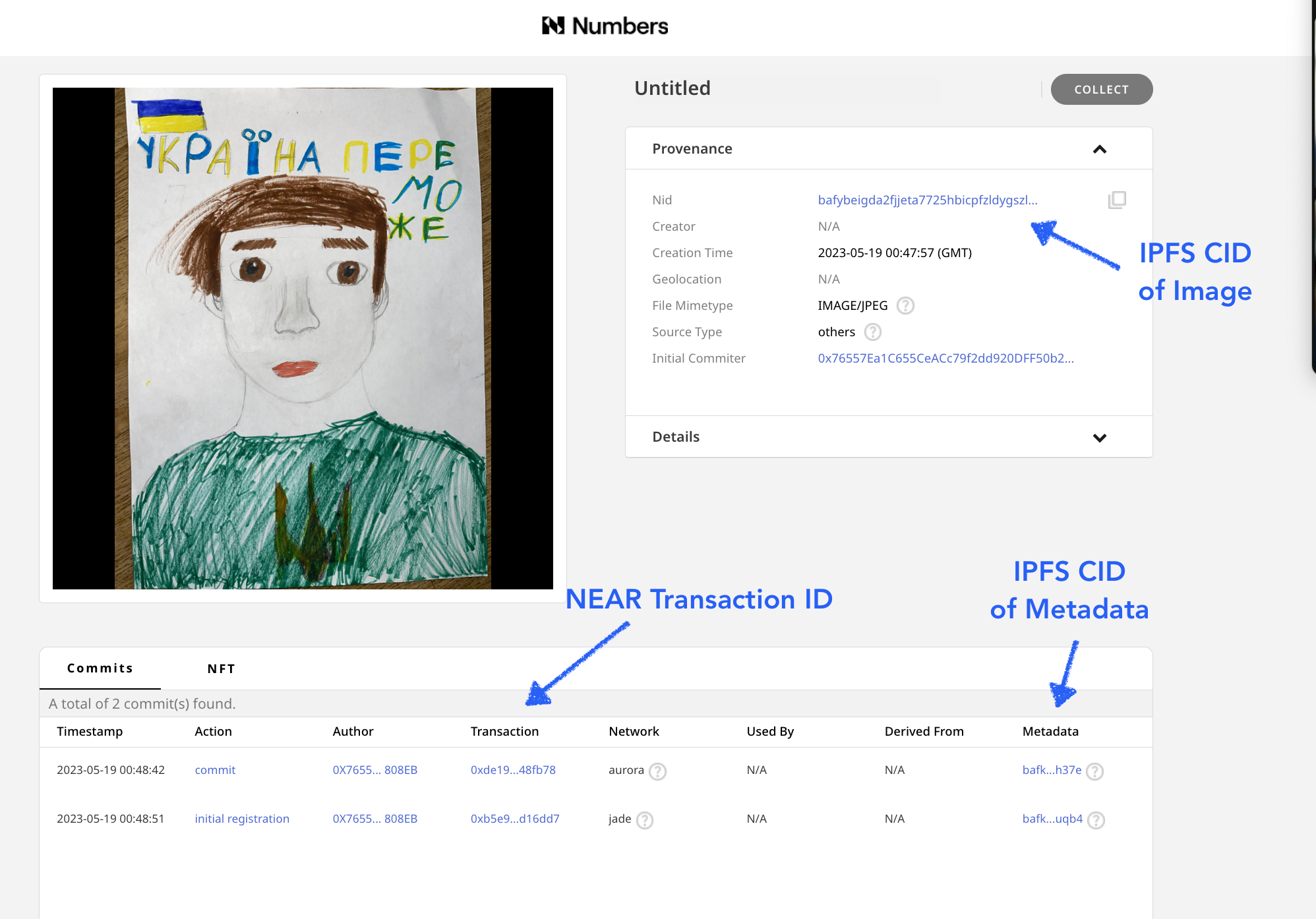
To register these assets, Starling Lab collaborated with the Numbers Protocol and also used the Starling Integrity pipeline to process the data and create publicly available registration records, publishing images and metadata records on IPFS. The records created include images of the drawings, along with a limited (redacted) set of metadata, which did not include certain identifying information, such as the children’s last names. See the example on Numbers Search.
The initial drawing and metadata record were both stored on IPFS with their IPFD CIDs stored on the NEAR blockchain and a registration of this record was added to Numbers Mainnet. Using the Numbers Protocol search, we can use the drawing’s IPFS CID to find the transaction containing all the information.
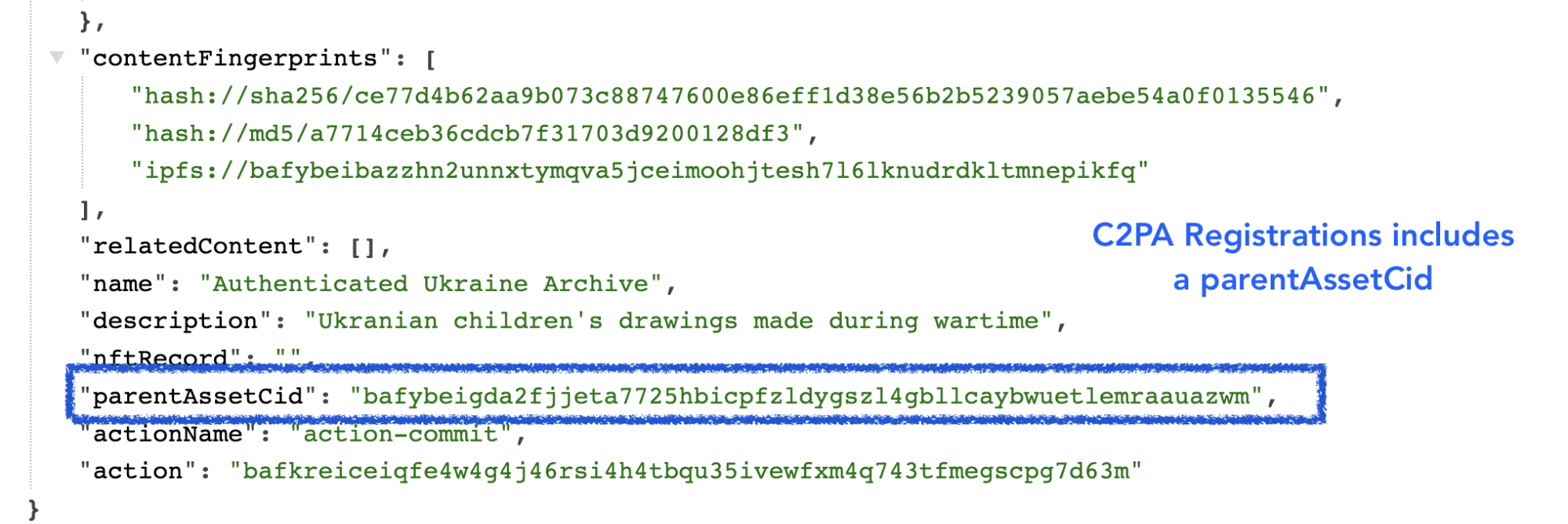
C2PA Registration
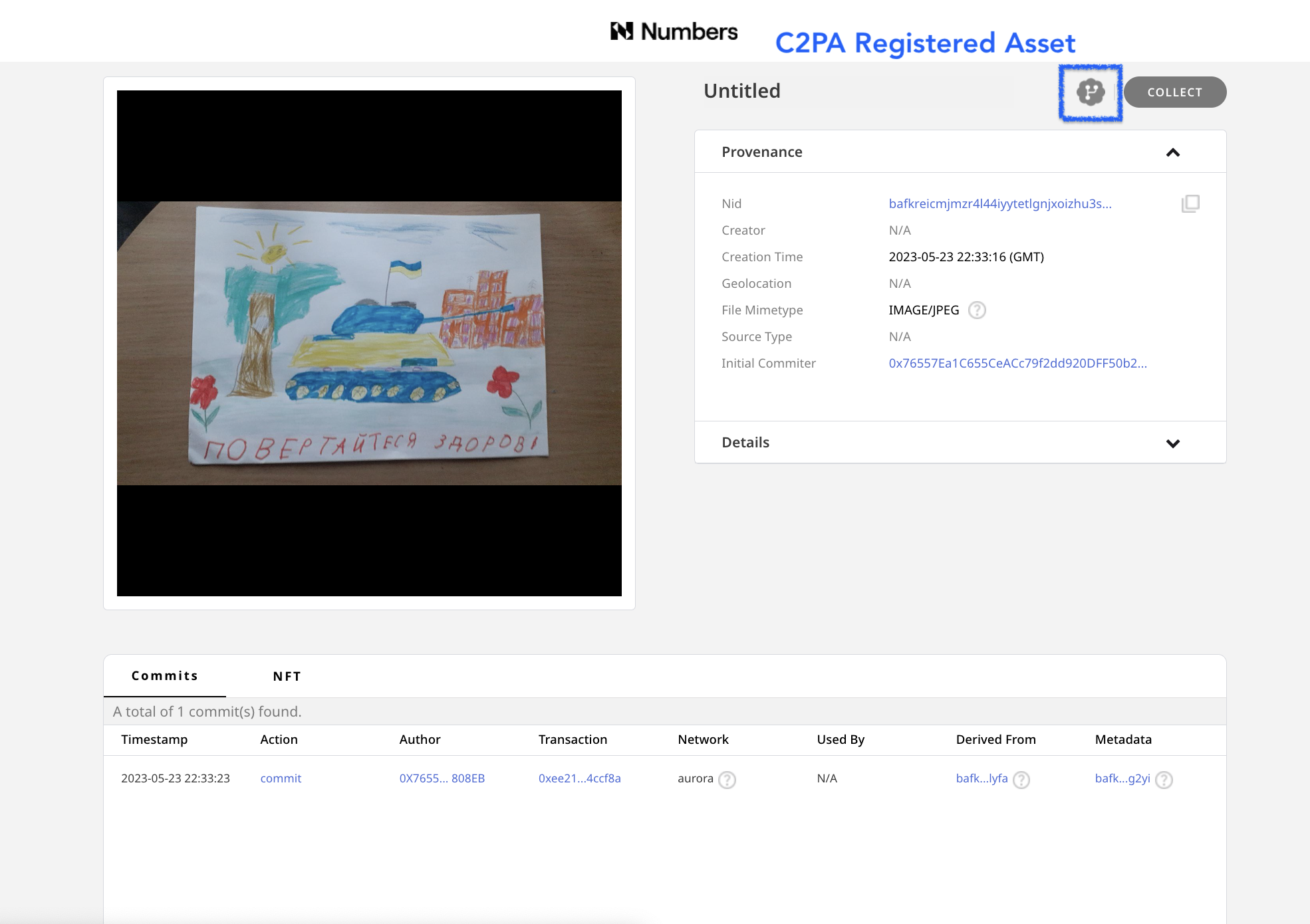
Once the regular versions of the drawing and metadata were registered, C2PA-compliant versions of these assets were also created.The presence of an icon next to indicates that an asset is one with C2PA metadata, and links back to the initially registered asset. The C2PA standard is a way of adding metadata that points versions of an asset back to the original asset, making an audit trail.
This makes it possible for anyone who may want to create verifiable, processed or modified versions (such as versions that are cropped or color enhanced for publication) of the drawings to create them, and connect them back to the original image with a record of any changes made.
The C2PA metadata added to the image is a standardized method used by tools such as Adobe Photoshop which allows each incremental edit to add a signed thumbnail and edit log to an image.
Starling Integrity Pipeline
All of the assets for this project were also bundled together, then registered and preserved using the Starling Integrity pipeline. This is a data processing pipeline that Starling Lab uses to bundle images with metadata, add registration certificates, encrypt, and add to various distributed storage and archival systems.
For this particular project, we used the Starling Integrity pipeline to zip complete copies of the image assets with private metadata including the last names of the children who made the drawing, then included authsign and OpenTimestamps certificates, and encrypted the file bundle. We then added these signed and encrypted files on Filecoin for archival storage, a cryptocurrency-collateralized archival storage system that will store the files for a duration committed by the set of storage providers, in this case 18 months, and run intermittent checks on the content to verify that the data is continuously preserved with the specified redundancy.
The archive itself is registered on NEAR using Numbers Protocol, as well as on the LikeCoin blockchain with ISCN.
Searching and Viewing Assets
The records for each drawing were archived by Starling Lab and the Numbers Protocol, with the CIDs & NEAR blockchain transaction IDs for the original drawing, the original metadata, as well as versions of these that have C2PA credentials, which allows one to understand the history and identity data attached to images that may need to be modified or edited.
For each drawing, you can view each of these four records using Numbers Search to:
- See the blockchain registration of these assets using a block explorer for NEAR or Numbers Mainnet.
- Inspect the images and sets of metadata on IPFS using the Numbers IPFS gateway.
- Use Filecoin explorer to see the archive of the assets.
- Download images and view C2PA-credentialed assets with the Verify tool.
Search for a Drawing and Metadata with a CID
In order to search and view the NEAR blockchain registrations with the Numbers Search tool, a user needs to have the asset CID provided from the list of archives. In order to search in a web browser, type in https://nftsearch.site/asset-profile?nid= followed by a CID, such as bafybeibazzhn2unnxtymqva5jceimoohjtesh7l6lknudrdkltmnepikfq
The resulting URL of the above C2PA-credentialed asset would look like: https://nftsearch.site/asset-profile?nid=bafybeibazzhn2unnxtymqva5jceimoohjtesh7l6lknudrdkltmnepikfq
Blockchain Registrations
The assets were registered on two blockchains. The basic information with the CID of the content stored on IPFS, plus a hash of the data (a check you can use to see if content you have, such as a copy of the drawing is the same as this registered version) is added to the Numbers Jade blockchain network. Next both the basic registration and more complete version of the asset’s metadata, which includes C2PA data, was registered on the NEAR Aurora blockchain.
The transactions where these are registered are linked from the Numbers Search interface and can also be found by appending the transaction ID to the following URLS
- Jade: https://mainnet.num.network/tx/<transaction ID>
- Aurora: https://explorer.mainnet.aurora.dev/tx/<transaction ID>
These registrations provide an immutable, timestamped record of the sha256 hash of the content, and can be used to verify whether or not any copy you may have of a drawing or it’s metadata are in fact identical to the version that was archived on the blockchain by Starling Lab and Numbers.
Viewing Data on IPFS
IPFS is a peer-to-peer protocol for sharing and hosting data and media. This is a resilient alternative to the client-server http-based web2 internet that can be accessed from web browsers using a gateway that bridges the http and IPFS networks.
Numbers Protocol hosts a gateway which you can use to view the IPFS copies of the drawings and metadata. To access these copies, you can click on a link in Numbers Search, or type in the gateway address along with the CID in any web browser: https://ipfs-pin.numbersprotocol.io/<CID>
Having this published on IPFS makes it easy to retrieve and inspect the images and metadata that has been registered on the different blockchain networks.
Viewing Filecoin Registration
Filecoin is a cryptocurrency (FIL) backed archival storage system. This system ensures archival storage on their network by the miners of their cryptocurrency. The protocol runs intermittent checks against sets of data that are archived, and if data isn’t stored, the miners (also known as storage providers) lose FIL collateral that they stake when they made the storage deal. The Starling Integrity pipeline used this to prepare and store these encrypted versions of the archive.
With the Filecoin CID Checker, you can view information about an archive, such as the identity of the node storing the data, the status of that archive, the deal made for the preservation, and the immutable content identifier or the payload that was submitted for storage. See the information about the MISW collection that was archived on Filecoin (Filecoin piece CID baga6ea4seaqdqgywa3n55hughvnfkroou6nm6qisqalzew7vy2vdqe3jfcr6wci), which includes all files, metadata, and a spreadsheet listing all assets.
Viewing C2PA assets with the Replay Tool
The Content Authenticity Initiative (CAI) is a group working together to fight misinformation and add a layer of verifiable trust to all types of digital content. Members of this group include those from media and tech companies, NGOs, academics, and more.
In February 2021, Adobe, Arm, BBC, Intel, Microsoft, and Truepic launched a formal coalition for standards development: The Coalition for Content Provenance and Authenticity (C2PA). These standards guide the development of tools, supported within Adobe editing tools such as Photoshop, that create public and tamper-evident records that can be attached to an image to understand more about what’s been done to it, where it’s been, and who’s responsible. These same standards were used to create metadata and records for the MISW collection.
With the Verify tool, you can download an image via IPFS from the MISW collection (adding a .jpg file extension), drop the image in the online tool, and inspect the image and data added according to the C2PA standards. If you were to edit the image with Photoshop, the hash of this record would change – however, you now have a tool that can tie this image back to the original, as well as show and compare any edits and changes made in Photoshop.
Conclusion
The project demonstrates the archival process for a valuable set of assets that create a record of the war in Ukraine to help future generations that want to understand this pivotal event in history, and helps create a reliable narrative of the past that may be used by future generations to help understand, make claims, and hold individuals and governments accountable and build a better future for humanity.
This set of tools not only creates an immutable archive of these assets, it also demonstrates the tools that can be used for the creation of an archive that is searchable and verifiable. It creates a set of assets that can be used in journalistic, legal, and historical depictions that allow those who may want to make minor edits to share these images with others by cropping, improving color, tone, and contrast, or make other minor edits, in a way that makes it possible for the public to understand the accuracy and veracity of these copies. Learn more about the collaboration with the Mom I See War Research and Numbers Protocol.

Archiving 10,000 Web Pages of Weaponized Narratives in support of the DFRLab
Store
We are thrilled to announce our participation in an extensive archiving initiative supporting the Atlantic Council’s Digital Forensic Research Lab (DFRLab). This significant project involves preserving 10,000 web pages as part of the research for the “Narrative Warfare” report, providing a robust resource for understanding the complex landscape of digital misinformation and information warfare.
The “Narrative Warfare” report, published by the DFRLab, delves into the intricacies of how narratives are weaponized in the digital age. The report uncovers how state and non-state actors manipulate narratives to influence public perception and destabilize societies.
The dataset of 10,000 web pages represents pro-Kremlin news publications from the 70 days prior to the ground invasion (Dec 16, 2021 to Feb 24, 2022). The team at the DFRLab identified and tracked five primary narratives pushed in support and ahead of the invasion of Ukraine.
Starling Lab, renowned for its pioneering work in data integrity and digital preservation, played a crucial role in this initiative. By leveraging advanced technologies and methodologies, Starling Lab ensured that the archived web pages were meticulously preserved and accessible for future research and analysis. This collaboration underscores the Lab’s commitment to safeguarding digital content and promoting transparency in the digital realm.
Methodology
Given the risk to the material once the report would be published, we preserved and durably stored the material on the request of the DFRLab. Director Andy Carvin’s team shared a spreadsheet containing, for each URL, original research metadata such as the associated broad narrative, the source pushing this narrative, and the article’s reach on social media.
Each page was crawled individually, meaning that all its content (media, code, style) were downloaded in a package permitting to “replay” it in the future and offline, independently of whether the original content would be deleted. Archives were prepared and packaged up using the cloud tools provided by WebRecorder, and all the content cryptographically signed by Starling Lab’s SSL certificate. For more details on these authenticated web archives, read our Dispatch on WACZ files.
The resulting dataset, totalling 400GB, can be accessed by members of the “Dokaz” initiative on request. While each page can be individually browsed as it was captured at the time, regardless of whether it went away, we are looking for support to produce an explorable, searchable interface to facilitate access for researchers.

Conclusion
In conjunction with the DFRLab’s “Dokaz” initiative, which focuses on preserving and verifying evidence in conflict zones, this archiving effort marks a significant step forward in the fight against digital misinformation. The “Dokaz” initiative, supported by Starling Lab, aims to provide reliable and verifiable digital evidence that can withstand scrutiny and support investigative journalism and research.
This collaborative effort between Starling Lab and DFRLab highlights the power of interdisciplinary partnerships in addressing the challenges posed by digital misinformation. By combining expertise in data integrity, digital forensics, and narrative analysis, this project not only enhances our understanding of narrative warfare but also strengthens our ability to counteract its harmful effects.
For more information, visit the Atlantic Council’s Narrative Warfare Report.