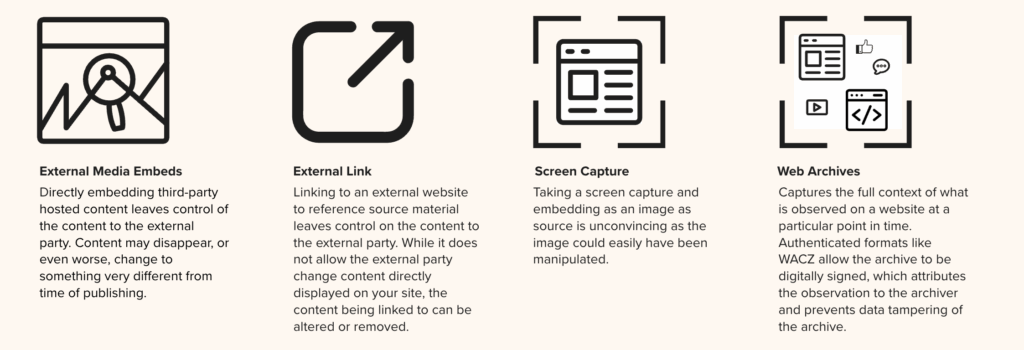
When A Screenshot Isn’t Enough

When A Screenshot Isn’t Enough
Starling Lab and the Associated Press teamed up to investigate the extent and implications of government monitoring, building an authenticated archive with evidence that had been posted online.
Reading Time: 5min


Contents
Background
Data can paint an intimate portrait of any person in modern society. In the hands of authorities, the way data is collected and used can present important privacy concerns.
During the early days of the COVID-19 pandemic, governments around the world got a firehose of individuals’ private health details – including photographs that captured people’s facial measurements and home addresses – to power surveillance tools that government officials said would help stop the spread of coronavirus.
For more than a year, Associated Press journalists interviewed sources and pored over thousands of documents to trace how some of those technologies marketed to “flatten the curve” were put to other uses. But most importantly, they wanted to understand who was impacted.
Working with staffers from Hyderabad, India, to Beijing to Jerusalem and Perth, Australia, the AP team found that authorities used these technologies and data to halt travel for activists and ordinary people, harass marginalized communities and link people’s health information to other surveillance and law enforcement tools. In some cases, data was shared with spy agencies.
India, which has been a global leader in tech development, provided a particularly interesting example. As the pandemic took hold in 2020, local police were tasked with enforcing mask mandates. The AP team soon saw via social media that officers had turned to facial recognition technology software to zero-in on people not wearing masks. But how were those facial scans being used?
When an AP reporter met with high-level police officials in Hyderabad, first they denied using facial recognition. But lower-level officers later divulged that they did, and could decide whose face they scanned in part based on who they deemed “suspicious.” That stoked fears among privacy advocates, some Muslims and members of Hyderabad’s lower-caste communities, who urged the journalists to press further.
Contents
Context
Garance Burke is a global investigative journalist from the Associated Press. As part of her Starling Lab journalism research fellowship, she wanted to incorporate new open-source methodologies into reporting on the misuse of surveillance tools deployed by authorities globally during the pandemic. Examples from her research would be displayed in an article entitled Police seize on COVID-19 tech to expand global surveillance, part of the award-winning Tracked series.
Working with Avani Yadav (a colleague at the University of California, Berkeley Human Rights Investigations Lab), Burke used open-source investigation methods to identify and authenticate social media posts and video/audio/photo material from police agencies and individual officers about their use of facial recognition and other AI-powered technologies in India. The team built spreadsheets of Twitter, WhatsApp, Reddit, Telegram, Facebook posts and began archiving that material using Hunchly.
Then, Burke turned to Starling Lab for assistance with the secure capture, authentication, and storage of this material.
Meanwhile, AP colleague Krutika Pathi continued to investigate police use of facial recognition cameras during the pandemic in predominantly Muslim neighborhoods. She and video journalist Rishabh Jain got rare access to police headquarters, allowing what they deemed a fair portrayal of the agency’s tech arsenal inside Hyderabad’s Command and Control Center. There, officers showed them how they run CCTV footage through facial recognition software that scanned images against a database of offenders.
Indian privacy advocates said these kinds of stepped-up actions under the pandemic could enable what they called “360 degree surveillance,” under which things like housing, welfare, health and other kinds of data are all linked together to create a profile.
Government officials would sometimes reveal more details about how they were using surveillance technology by posting about their methods on social media. A 2020 tweet from the police chief of Telangana state included photos of unsuspecting locals with colored rectangles overlaid on their maskless faces, apparently automated by their new tools. The following year, police shared photos of themselves using handheld tablets to scan people on the street using facial recognition.
These sorts of posts added more dimension to the story, but could be deleted later on. Entire accounts could be suspended or set to private. In order to preserve such ephemeral records – and to prevent future denialism – posts and other webpages in this reporting would need to be carefully archived and published in a verifiable way.
Contents
Framework
Starling Lab uses several technologies to implement its three-part framework of Capture, Store, Verify. In this project, Starling Lab employed web archiving tools to document how surveillance technology was used not only to control the spread of COVID-19, but also as a means of social surveillance. The framework was applied to capture high quality and authenticated archives of social media posts and other web-based evidence.
The Challenge
Research and data collection for this project was done in the summer and fall of 2022. The goal was comprehensive capturing and archiving of social media pages in a way that preserved the full context of the website.
AP uses several methods to save web content in their traditional research and documentation workflow. A simple option is to take screenshots or similar screen captures of websites. They might also refer to old snapshots taken of webpages by the Internet Archive’s Wayback Machine. Within their stories, they might also embed content (like a Twitter post) directly from a website using a simple API format called oEmbed.
Unfortunately, externally-hosted methods mean reliance on a single, centralized entity to keep these resources available on the web. These sites could go offline, and artifacts and evidence can be altered in a way that is not evident to end users. The Wayback Machine has faced attacks from hackers. Google announced that its URL shortening service – which content links may depend on – will be shut down and all historical links will break.
Screen capture, on the other hand, may have its authenticity called into question as an image can easily be tampered with – especially in the age of generative AI.
Different editors and reporters use different methods for managing content and resources gathered for an article. These might include Google Drive, Microsoft OneDrive, or Dropbox. They might also create a shared document with a list of links and resources. As a whole, there is no standard process for keeping notes and managing the content gathering. This isn’t unusual for a large, spread out organization, when there are a lot of different processes that work for each individual unit.
During the investigation phase for this story, reporters and investigators used web archiving tools such as Hunchly to keep records on local machines, cloud drives, and on AP secure servers.
Once stories are developed, one of two Content Management Systems (CMSs) are used for publishing content. The primary CMS used is an in-house custom built tool designed for authoring and publishing content. This system supports text, photo, and video media types. Formats for full web archives (ex: WARC or WACZ) cannot be directly embedded, and therefore screen captures and external resource linking are common ways to include such evidence in stories.
Contents
The Prototype
This was Starling Lab’s first project involving the capture and display of web pages. In this case, social media posts were the primary focus, especially given their vulnerability to disappearance. In order to preserve this evidence, Starling Lab worked with Webrecorder to implement their suite of tools that can capture authenticated web archives. We then stored them using decentralized systems, and embedded web archives directly in an AP story for readers to explore the rich context and authenticity information packaged into the archive.
Burke served as the point person translating and coordinating technical needs across the Starling engineering and AP teams. AP’s then-data editor Justin Myers ran point on implementing the technical requirements on the AP CMS.
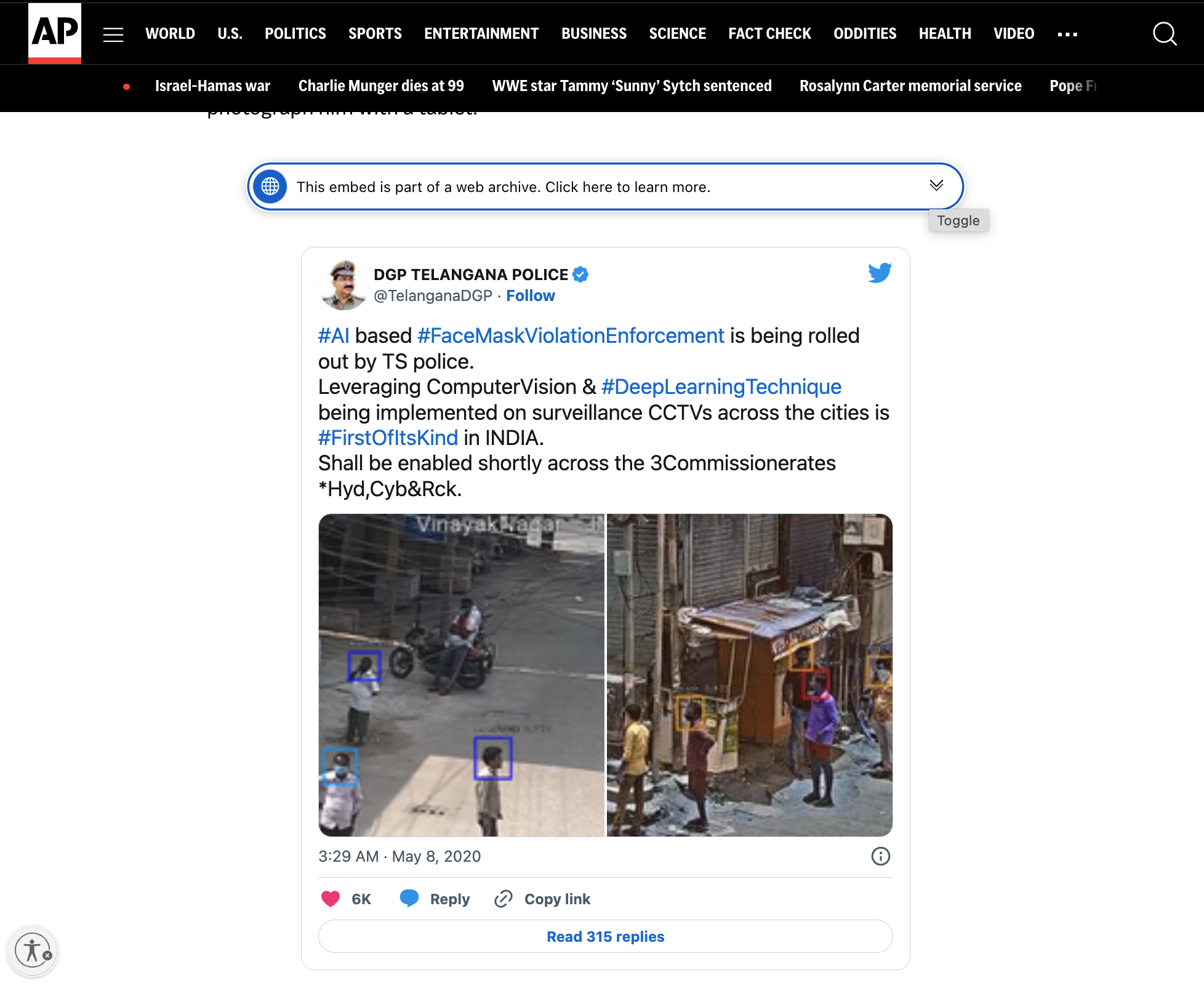
Through this collaboration with Starling Lab, the AP team was able to capture dozens of verifiable social media posts using Webrecorder. The team put together a collection of web archive files that were cryptographically hashed, signed, and preserved in redundant storage systems, with a public record of exactly what was captured – and when – using blockchain registrations. To support content verification by general audiences and other investigators, an authenticated web archive is embedded in the article on AP’s website. It includes authenticity information, and the archive file itself can be downloaded for independent auditing.
Contents
Technology
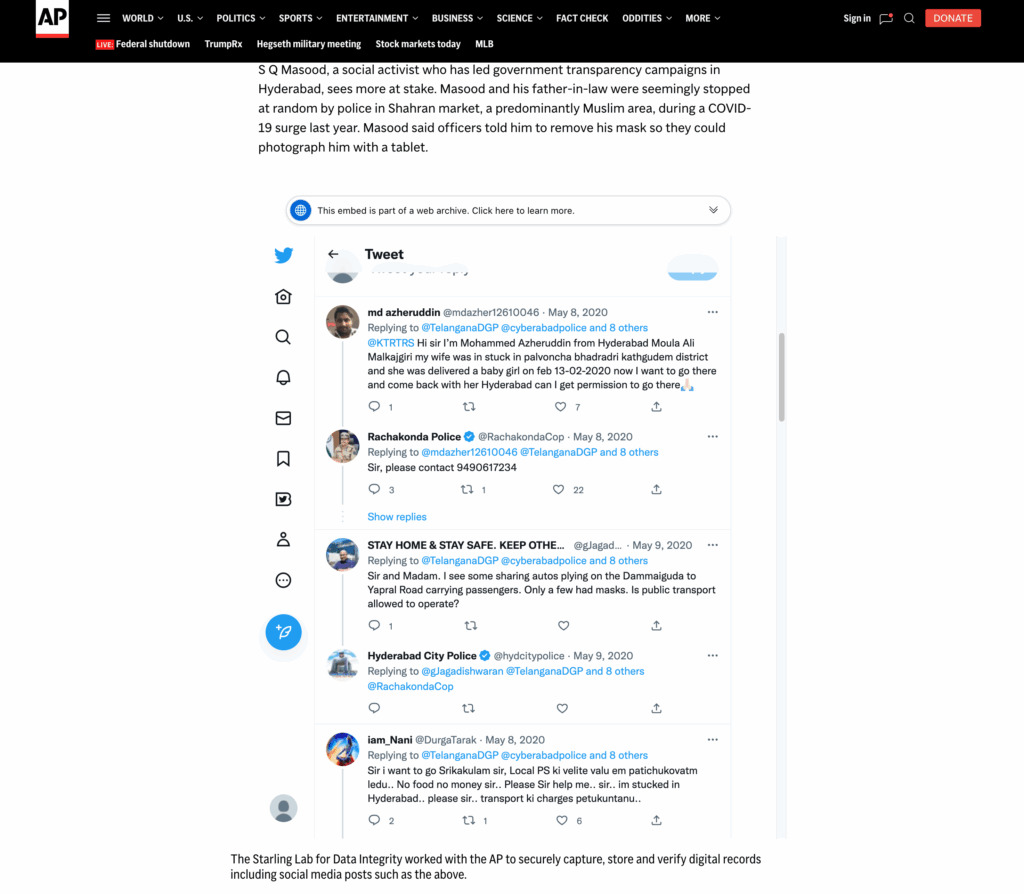
The Webrecorder suite of tools makes it possible to capture a snapshot of a website at a certain point in time, including all the individual elements such as embedded photos, links, scripts, and other types of media on the page. For example, when capturing a social media post, comments by other users, including usernames and profile pictures are also preserved in the web archive. This produces an interactive copy of a website that can be embedded in articles, even if the originals are removed from the original location on the web.
Starling Lab engineers and the AP team developed a workflow that would enable the capture of dozens of social media posts using Webrecorder. The tools are paired with the Starling Framework for Integrity—Capture, Store, Verify—to ensure records of their authenticity are not only contained within the web archives, but also registered on immutable ledgers and the archive content themselves are redundantly preserved on distributed storage networks.
Capture
Identifying Web Content for Archiving
During the investigation, Burke first identified records that were at risk of being wiped from the internet. These include PDF files, social media posts, photos, videos, leaked documents, and more.
An important part of this process is also the identification of effective and efficient data scraping tools/techniques, and setting up a central repository that can be collaboratively worked on. To accomplish this, reporters from AP emailed lists of links that they wanted to capture, and the list was added to a self-hosted version of Browsertrix operated by Starling Lab. The sites were crawled and the produced web archives were signed with a Starling signing certificate to ensure this “observation” of the website is attributable to Starling, who conducted the web crawl. These produced web archives are shared with AP with cloud storage.
Producing Web Archives with Webrecorder Tools
Using the open source software developed by Webrecorder, namely Browsertrix, the Starling team was able to capture authenticated and high fidelity websites identified by AP. These include web applications containing content that is highly interactive, such as social media posts where comments are dynamically loaded as a user scrolls through the comment feed.
Browsertrix downloads everything that exists on a web page in a zipped archive called a WACZ file. A WACZ file is a copy of the code and media that makes up that webpage, and the package includes an index of what content was captured and provenance information about the downloaded content such as cryptographic hashes, signatures using Authsign, and information about the Webrecorder tool used to produce the WACZ file. When users later display (or “replay”) the page using ReplayWeb.page, it remains fully interactive as the original content, and progressively verifies the loading content against its hash and signature to ensure elements of the page have not been tampered.
While Browsertrix was used to crawl a long list of websites and was able to handle most dynamically loaded content, some types of websites evade automated crawling. For example, one of the PDF files was behind a CAPTCHA, which required a human to solve. In this instance, the Starling team employed another Webrecorder tool—ArchiveWeb.page, to manually crawl the site.
In the case of Twitter posts, Webrecorder developed one specialized tool—OEmbed, to help render the embeddable version of a post. Anticipating that articles would prefer to embed the cleaner embeddable view, the team crawled both the original Twitter link and the version rendered through embedded, in the same WACZ file. For example:
- On Twitter: https://twitter.com/TelanganaDGP/status/1258675268924739584
- Through oEmbed: https://oembed.link/https://twitter.com/TelanganaDGP/status/1258675268924739584
This way, both versions of the snapshotted site can be inspected, to ensure that the content is not altered in the oembed.link domain.
Ensuring Web Archives are Authentic and Tamper-evident
The Webrecorder team developed the Authsign specification and tools so WACZ files can be authenticated at the time they are produced. The technology relies on using Let’s Encrypt certificates associated with a domain name to sign content fingerprints in the web archive. This allows the operator, in this case Starling, who is observing the web to produce web archives to attest to the authenticity of the content using their domain name.
In addition to the built-in authenticity mechanism of WACZ files, Starling also used its integrity pipeline to register the WACZ files themselves on immutable ledgers. Nine of the files from the Tracked series were registered using the Numbers Protocol on the Avalanche blockchain (a fast, decentralized, open-source blockchain that offers smart contract functionality) and using the ISCN standard on the LikeCoin blockchain (a chain specialized for decentralized publishing).
Store
Unlike web archives hosted on platforms like the Internet Archive, WACZ files have content and authenticity information self-contained and can therefore be stored anywhere. For example, AP stores each WACZ file in a S3 bucket, meanwhile Starling has them stored on our internal systems as well as on the Filecoin distributed storage network. This prevents censorship risks associated with centralized storage providers.
Verify
In order to display a web archive as embedded content on an article, Webrecorder provides scripts that developers can use to “animate” a WACZ archive referenced. In this article from the AP Tracked series, about 2/3 of the way down, is an example of an archived Tweet. The version on this page is an example of the OEmbed-filtered embeddable version of the Tweet.
During this collaboration, the Webrecorder team worked with Starling to develop a UI element that allows readers to view provenance information of the web archive they are interacting with. They can see the URL crawled, the producer of the Authsign signature and their signing certificate, among other authenticity data, as well as a button to download the original archive that they can import into ReplayWeb.page to independently explore.
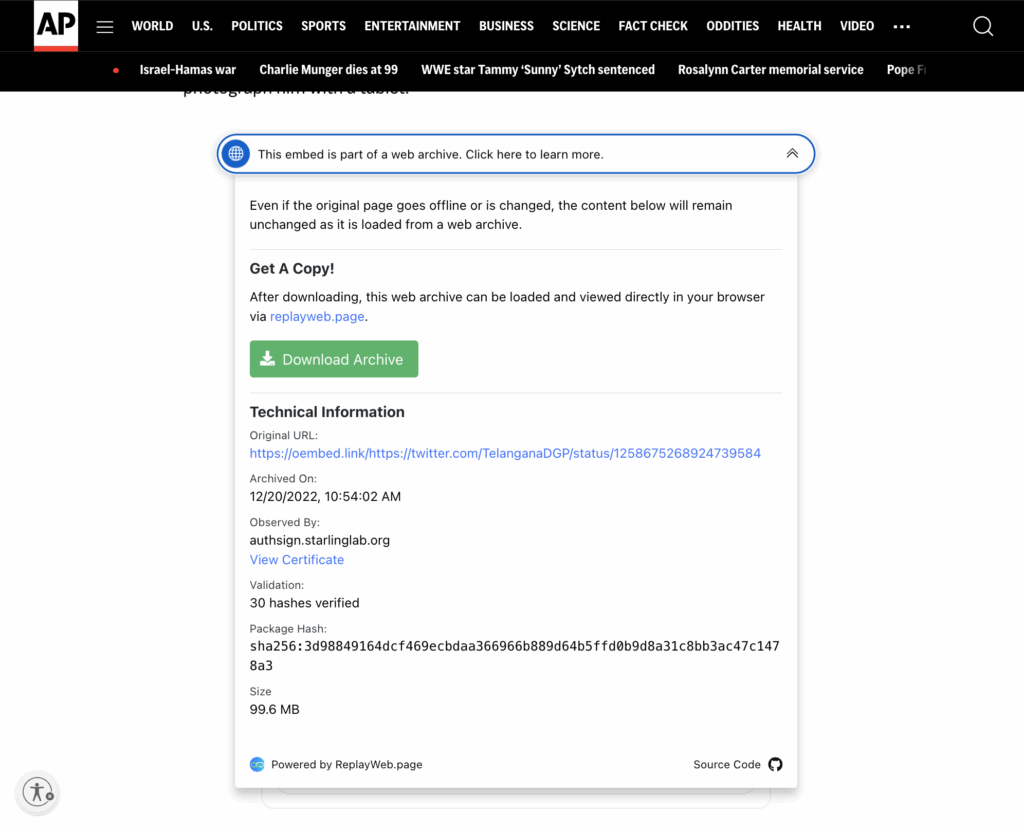
When the downloaded WACZ file is imported into ReplayWeb.page, two URLs are available to be explored. They represent the oEmbed version (as displayed on the AP site) and the original Tweet crawled from Twitter directly.
Unlike a simple screen capture, each individual element is captured independently, and can be inspected as their original resource.
Readers can scroll through the comments, and for example, playback videos that is captured from the comment section.
This native support for verification workflow offers clear benefits to adopt authenticated WACZ files for evidence collection and preservation. Additionally, the self-contained nature of WACZ files, when paired with the Starling Framework for Data Integrity allow flexible registration and preservation strategies that enhance the provenance and availability of WACZ files themselves.
Contents
Learnings
Quality Assurance of Crawled Pages
Throughout the investigation, many links were submitted to Browsertrix for web archiving. Although Browsertrix is one of the best web archiving tools, automated crawling of websites is inherently a tricky procedure. For example, the content of interest may be behind a popup dialog, or requiring page scrolling in order to load, or at the time of the crawl the content somehow failed to load. To reliably determine whether a web archive captures the content of interest, human inspection is necessary.
At the time of the investigation, Browsertrix did not have an integrated review system, which means each time we discovered a web archive that failed to capture the content of interest, we had to resubmit the crawl, and if automated crawl is not possible, we would have to opt for a manual crawl by scrolling through the page to load the content of interest in the browser.
In order to streamline the quality inspection process, Starling discussed with Webrecorder a review system within Browsertrix that allows the user to first playback the web archive within the platform, then approving or resubmitting for crawl. Browsertrix now has added a review and tagging system to support this workflow.
Scheduling Recurring Crawls
Another feature AP requested was the ability to schedule crawls of a website on a regular basis, as some sites have content that changes over time, and also as a way to monitor whether site content or social media posts are taken down. An additional bonus feature would be to monitor when and if a social media post is taken down.
At the time of this investigation, Browsertrix’s scheduling feature was still in development, so we did not schedule recurring crawls, although links were often crawled at multiple points in time through manual submission. It is now possible to automate recurring crawls using Browsertrix, which would be useful for future investigations. Watching for changes, or content disappearance, over time, remains an item on AP’s wishlist.
Embedding a Web Archive in an Article
To embed an archived Tweet, we need to load a JavaScript plugin on the AP website. However, Content Security Policy (CSP) on AP’s website prevents loading of resources from other domain names, which prevents us from using a copy of the ReplayWeb.page component from a content distribution network (CDN).
To resolve this, the team decided to host the ReplayWeb.page component directly on apnews.com, which is an exception to the standard content management workflow, and involved unanticipated operational overhead to execute. This has a direct impact on the maintainability of our site going forward because the component needed to be kept up to date and each update required additional verification. The correct rendering of this article now depends on the ReplayWeb.page component, and therefore is more brittle than regular text and image articles.
The WACZ files themselves are stored in, and loaded from, Amazon S3 buckets. Here we encountered another problem related to web security. While CSP prevents the AP site from including resources from other domains, Cross Origin Resource Sharing (CORS) protects resources from being inserted into other domains. Browsers will block resources loaded from a different domain than the website unless the remote resources explicitly allows for such behavior. This is a security measure to prevent an attacker from making unauthorized requests on behalf of the user. To resolve this we simply had to configure S3 to allow all origins when sending the WACZ resource.
Attesting to the Creation of a Web Archive
To create a web archive, one needs to crawl the website and record the content into WACZ format. It is crucial for the organization conducting the crawl to add a claim that this archive is based on their observation of the website. Starling Lab explored with AP several arrangements for making these attestations, which are secured by digital signatures.
In this implementation, the Browsertrix crawling service is operated by Starling, acting in collaboration with AP, so it is debatable as to who should be signing these attestations of creation. In other words, who should be responsible for maintaining the signing certificate for these web archives, which is associated with an organization’s domain name.
Some of the options explored include:
Pointing an AP subdomain to a Starling-operated signing server, so Starling can generate signing certificates (with AP’s domain) to attest to crawls conducted by Starling on AP’s behalf. This was deemed unacceptable from an information security perspective by AP’s technology team.
Having AP operate a signing service that will sign whatever is presented to it by authorized Starling crawl servers. This was also too much of a security risk for AP’s technology team, as they have little control over what web archives Starling sends to them, and their signing service would blindly attest to them.
Having Starling sign the archives with a Starling domain name. This way, Starling is not signing on behalf of AP, but rather signing on its own behalf. AP will simply publish an archive attested to by Starling.
Despite AP’s signature being more publicly recognizable, the team ultimately decided to take the path of having Starling sign the web archives with its signing certificate, because there is no straightforward way for AP to ensure proper use of their signing certificate unless the news organization operates the web archiving platform themselves. AP may of course speak to Starling as a reliable collaborator, but the digital signature should be from the creator of the web archives.
Contents
Archive
News Articles
- AP News, December 20, 2022 Police seize on COVID-19 tech to expand global surveillance
- AP News, Tracked Series landing page
- Pulitzer Center Update, Garance Burke, June 2023 – Tracked: How AP Investigated the Global Impacts of AI
Awards and Recognition
- National Headliner Awards – First place for “Public service in newspapers in top 20 media market”
- News Leaders Association – finalist for First Amendment Award
- Clarion Awards (Association for Women in Communications) – winner for Newspaper Investigative Series
- Deadline Club Awards (NYC Society of Professional Journalists) – finalist for “Science, Technology, Medical or Environmental Reporting”